| CPC G06F 40/295 (2020.01) [G06F 16/3344 (2019.01); G06F 40/247 (2020.01); G06N 3/044 (2023.01); G16H 70/60 (2018.01)] | 17 Claims |
|
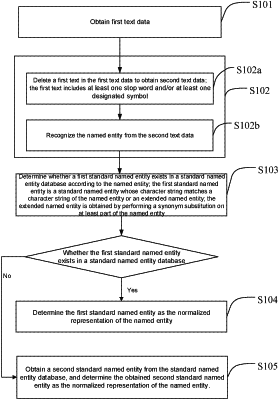
1. A normalized processing method of a named entity, comprising:
obtaining first text data;
recognizing a named entity from the first text data;
determining whether a first standard named entity exists in a standard named entity database according to the named entity, the first standard named entity being a standard named entity whose character string matches a character string of one of the named entity and an extended named entity, and the extended named entity being obtained by performing a synonym substitution on at least part of words of the named entity;
determining the first standard named entity as a normalized representation of the named entity in response to determining that the first standard named entity exists in the standard named entity database; and
obtaining a second standard named entity from the standard named entity database, and determining an obtained second standard named entity as the normalized representation of the named entity in response to determining that the first standard named entity does not exist in the standard named entity database, the second standard named entity being a standard named entity whose word vector similarity to the named entity in the standard named entity database satisfies a preset condition, wherein obtaining the second standard named entity from the standard named entity database, includes:
determining a word vector similarity between each standard named entity in the standard named entity database and the named entity based on a word vector similarity matching algorithm; and
determining the standard named entity whose word vector similarity to the named entity in the standard named entity database satisfies the preset condition as the second standard named entity, wherein determining the word vector similarity between each standard named entity in the standard named entity database and the named entity based on the word vector similarity matching algorithm, includes:
calculating a length of a longest common subsequence of the named entity and each standard named entity in the standard named entity database;
sequencing standard named entities in the standard named entity database to obtain a standard named entity candidate list according to lengths of the longest common subsequences; and
sequentially inputting each standard named entity in the standard named entity candidate list and the named entity into a semantic model based on a word vector, so as to obtain the word vector similarity between the named entity and the standard named entity, wherein the semantic model based on the word vector includes a bi-directional encoder representation from transformers (BERT) model; and a fully connected layer of the BERT model is implemented by using a softmax classifier or a sigmoid classifier.
|