| CPC G06F 40/194 (2020.01) [G06F 16/3347 (2019.01); G06F 16/338 (2019.01); G06F 40/284 (2020.01)] | 20 Claims |
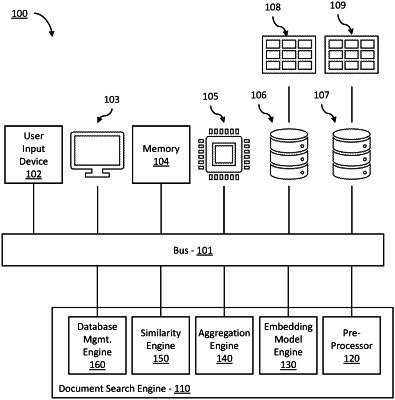
|
1. A method comprising:
accessing, by at least one processor, a training set of stored documents;
wherein the training set of stored documents comprise:
at least one existing pair of stored documents representing at least one pair of stored documents that are similar to each other, and
at least one non-existing pair of stored documents representing at least one pair of stored documents that are not similar to each other;
generating, by the at least one processor, a plurality of initial stored document word embeddings within each stored document of the set of stored documents;
wherein the plurality of initial stored document word embeddings comprise a plurality of stored document vector representations of a plurality of words in text of each stored document;
determining, by the at least one processor, an average stored document word embedding vector for the plurality of initial stored document word embeddings for each stored document;
utilizing, by the at least one processor, a similarity model to determine a similarity metric of a similarity between a first stored document and a second stored document of each candidate pair of a plurality of candidate pairs of stored documents in the set of stored documents based at least in part on the average stored document word embedding vector of each of the first stored document and the second stored document;
generating, by the at least one processor, a plurality of refined stored document word embeddings for each stored document in the set of stored documents by backpropagating an error of the similarity metric of each candidate pair, wherein the error is based at least in part on the at least one existing pair and the at least one non-existing pair;
generating, by the at least one processor, a refined average stored document word embedding vector for the plurality of refined stored document word embeddings for each stored document;
receiving, by the at least one processor, a search query from a computing device associated with a user;
wherein the search query comprises an input document having text;
generating, by the at least one processor, a plurality of input document word embeddings within the input document;
wherein the plurality of input document word embeddings comprise a plurality of vector representations of a plurality of words in the text of the input document;
determining, by the at least one processor, an average input document word embedding vector for the plurality of input document word embeddings for the input document;
utilizing, by the at least one processor, the similarity model to determine an input document similarity metric of an input document similarity between the input document and each stored document in the set of stored documents based at least in part on the average input document word embedding vector and the refined average stored document word embedding vector of each stored document; and
instructing, by the at least one processor, the computing device to display a ranked list of stored documents in response to the search query.
|