| CPC G06F 21/6254 (2013.01) [G06N 3/045 (2023.01); G06N 3/048 (2023.01); G06N 3/084 (2013.01)] | 23 Claims |
|
1. An auto-encoder system for anonymizing data associated with a population of entities, the system comprising:
a computer memory storing specific computer-executable instructions for a neural network, wherein the neural network comprises: an input node; a first layer of nodes for receiving an output from the input node; a second layer of nodes positioned downstream of the first layer of nodes; a third layer of nodes positioned downstream of the second layer of nodes; and an output node for receiving an output from the third layer of nodes to provide an encoded output vector; wherein the second layer of nodes includes a number of nodes that is greater than a number of nodes in the first layer of nodes and is greater than a number of nodes in the third layer of nodes;
one or more processors in communication with the computer-readable memory, wherein the one or more processors are programmed by the computer-executable instructions to at least:
obtain data identifying a plurality of characteristics in a human readable text comprising one or more letters or numbers associated with at least a subset of the entities in the population;
prepare a plurality of input vectors that include more than one of the plurality of characteristics, wherein the characteristics appear in the respective input vectors in a human recognizable form; and
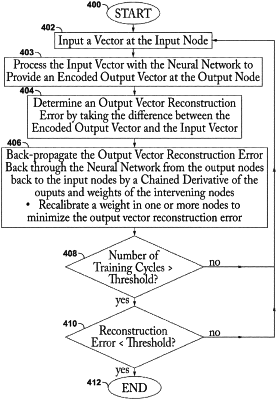
train the neural network with the plurality of input vectors, wherein the training comprises a plurality of training cycles wherein the training cycles comprise: inputting one of the input vectors at the input nodes; processing said input vector with the neural network to provide an encoded output vector at the output nodes; determining an output vector reconstruction error by calculating a function of the encoded output vector and the respective input vector; back-propagating the output vector reconstruction error back through the neural network from the output nodes back to the input nodes by a chained derivative of the outputs and weights of the intervening nodes; and recalibrating a weight in one or more of the nodes in the neural network to minimize the output vector reconstruction error;
wherein a plurality of the encoded output vectors during training include at least one of the plurality of characteristics recognizable for comparison by a processor to identify two or more encoded output vectors with a common characteristic but wherein said plurality of the encoded output vectors does not contain said at least one of the plurality of characteristics in a human recognizable form.
|