| CPC G06F 16/93 (2019.01) [G06F 16/285 (2019.01); G06F 16/3344 (2019.01); G06F 16/358 (2019.01); G06F 16/5846 (2019.01); G06F 16/906 (2019.01); G06N 3/044 (2023.01); G06N 3/09 (2023.01); G06N 20/00 (2019.01); G06N 20/20 (2019.01)] | 9 Claims |
|
1. A computer-implemented method comprising:
generating, using one or more processors and an attention-based text encoder machine learning model, and based at least in part on an unlabeled document data object, an unlabeled document word-wise embedded representation set for the unlabeled document data object, wherein the attention-based text encoder machine learning model is: (i) configured to generate a word-wise embedded representation set for an input document data object, and (ii) is generated by:
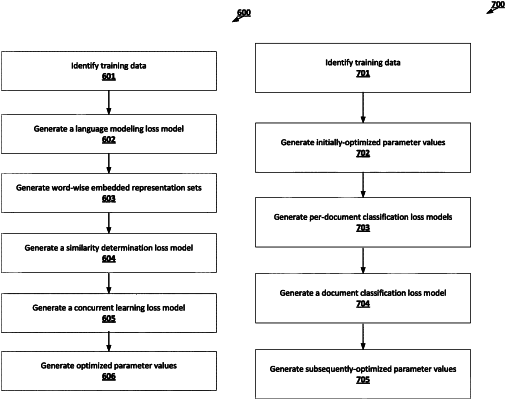
identifying one or more training input document data objects respectively associated with one or more ground-truth label classifications,
generating, during a first model training stage, one or more initially-optimized parameter values for one or more trainable parameters of the attention-based text encoder machine learning model using a language modeling loss that is defined in accordance with one or more first training objectives for satisfying a text reconstruction sub-task based at least in part on the one or more training input document data objects,
generating, using the attention-based text encoder machine learning model, a training word-wise embedded representation set for a training input document data object of the one or more training input document data objects,
generating, using a document classification machine learning model and based at least in part on the training word-wise embedded representation set for the training input document data object, an inferred document classification for the training input document data object,
generating based at least in part on the inferred document classification for the training input document data object and a ground-truth document classification for the training input document data object a document classification loss, comprising a cross-entropy loss, for the one or more training input document data objects, wherein the document classification machine learning model is trained by optimizing the document classification loss, and
generating, during a second model training stage, one or more subsequently-optimized parameter values for the attention-based text encoder machine learning model using a sequential learning loss comprising the document classification loss modified in accordance with a sequential learning regularization factor that describes computed effects of a plurality of update options to the one or more initially-optimized parameter values, wherein the sequential learning regularization factor is determined based at least in part on: (i) a per-parameter update magnitude measure that is determined based at least in part on an initially-optimized parameter value for a particular trainable parameter and a potential parameter value for the particular trainable parameter, and (ii) a differentiation measure for the language modeling loss with respect to the particular trainable parameter; and
generating, using the one or more processors and the document classification machine learning model and based at least in part on the unlabeled document word-wise embedded representation set, a document classification.
|