| CPC G06F 16/3346 (2019.01) [G16B 30/10 (2019.02); G16B 40/20 (2019.02)] | 20 Claims |
|
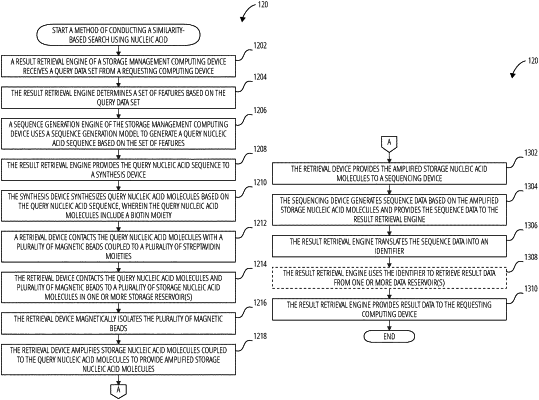
1. A method of performing a search for information data sets similar to a query data set in a database that stores information in a plurality of storage nucleic acid molecules, the method comprising:
determining a set of features based on the query data set;
determining a query nucleic acid sequence based on the set of features, wherein a degree of complementarity with the query nucleic acid sequence is correlated with a degree of similarity with the set of features;
synthesizing one or more query nucleic acid molecules based on the query nucleic acid sequence;
contacting the one or more query nucleic acid molecules with the plurality of storage nucleic acid molecules so that the one or more query nucleic acid molecules hybridize with the plurality of storage nucleic acid molecules to a degree that varies based on a degree of similarity between the set of features based on the query data set and sets of features represented by the storage nucleic acid molecules;
amplifying storage nucleic acid molecules coupled to the one or more query nucleic acid molecules to provide amplified storage nucleic acid molecules;
generating sequence data based on the amplified storage nucleic acid molecules;
translating the sequence data into result data for the search; and
presenting the result data for the search sorted by similarity to the query data set.
|