| CPC G06F 16/2471 (2019.01) [G06F 16/278 (2019.01)] | 29 Claims |
|
1. A computer-implemented method comprising:
obtaining, by at least one worker node of a distributed query execution environment, a chunk of data, wherein the chunk of data comprises a plurality of records associated with a query;
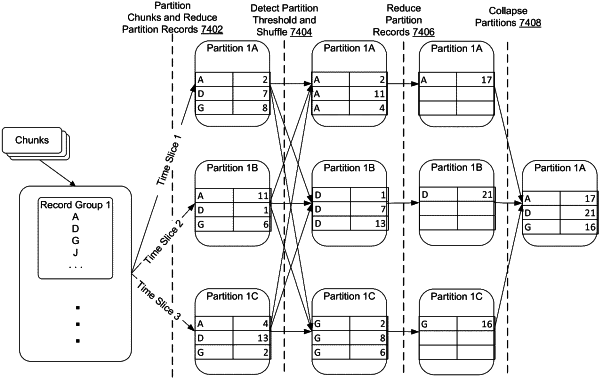
assigning records of the plurality of records to individual data partitions of a set of data partitions at the at least one worker node, wherein individual partitions of the set of data partitions correspond to distinct portions of physical data storage of the at least one worker node;
based on a number of data partitions exceeding a threshold value, combining records across partitions within the set of partitions, wherein combining records across partitions within the set of partitions combines records sharing a field value into a particular partition;
combining the records sharing the field value in the particular partition into a single record having the field value; and
reducing a number of partitions in the set of partitions by: selecting an additional partition from the set of data partitions to be aggregated with the particular partition, wherein the additional partition is selected from among the set of data partitions based on the additional partition having a highest number of records, among the set of data partitions, that does not exceed a maximum number of records allowable within the additional partition, aggregating records of the particular partition with records of the additional partition by relocating at least the single record having the field value from the distinct portion of physical data storage corresponding to the particular partition to the distinct portion of physical data storage corresponding to the additional partition, and removing the particular partition from the at least one worker node.
|