| CPC G06F 16/24568 (2019.01) [G06F 16/252 (2019.01); G06F 16/278 (2019.01)] | 20 Claims |
|
1. A system, comprising:
one or more computing devices comprising respective processors and memory configured to implement a control plane;
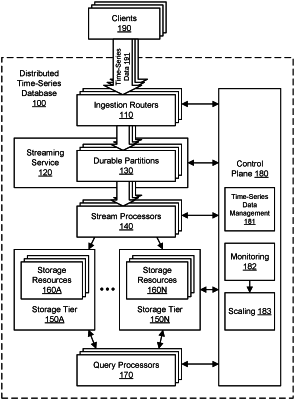
a plurality of computing devices comprising respective processors and memory configured to implement a fleet of ingestion routers, wherein the fleet of ingestion routers is configured to:
receive time-series data generated by a plurality of client devices, wherein the time-series data is associated with a plurality of time series, and wherein an amount of the ingestion routers is determined by the control plane based at least in part on an ingestion rate of the time-series data; and
partition the time-series data based at least in part on the plurality of time series to generate partitioned time-series data;
one or more persistent storage resources comprising a plurality of durable partitions, wherein the one or more persistent storage resources are configured to store individual partitions of the partitioned time-series data sent from the fleet of ingestion routers in respective ones of the plurality of durable partitions;
a plurality of computing devices comprising respective processors and memory configured to implement a fleet of stream processors, wherein an amount of the stream processors in the fleet is determined by the control plane based at least in part on the partitioned time-series data in the durable partitions, wherein the fleet of stream processors is configured to:
retrieve the time-series data, stored by the fleet of ingestion routers, from the durable partitions maintained at one or more persistent storage resources of the streaming service;
send a first one or more elements of the retrieved time-series data to a first storage tier; and
send a different second one or more elements of the retrieved time-series data to a second storage tier; and
a plurality of storage tiers, including the first storage tier and the second storage tier, respectively different from the one or more persistent storage resources, wherein individual ones of the plurality of storage tiers are different from and communicatively coupled over a network to respective ones of the fleet of stream processors, wherein a retention period for the first storage tier differs from a retention period for the second storage tier, wherein a performance characteristic for the first storage tier differs from a performance characteristic for the second storage tier, and wherein the individual ones of the plurality of storage tiers are configured to store the retrieved time-series data sent from the fleet of stream processors; and
a plurality of computing devices comprising respective processors and memory configured to implement a fleet of query processors configured to access time-series data stored in the first storage tier and the second storage tier, wherein individual ones of the fleet of query processors are each different from individual ones of the fleet of stream processors.
|