| CPC G06F 11/3664 (2013.01) [G06F 8/433 (2013.01); G06F 8/71 (2013.01); G06F 9/3891 (2013.01); G06F 9/45558 (2013.01); G06F 2009/45562 (2013.01); G06F 2009/4557 (2013.01)] | 20 Claims |
|
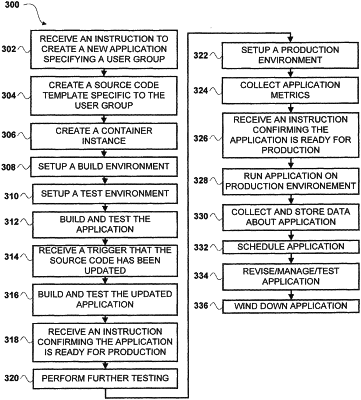
1. A method of managing a lifecycle of a big-data application, comprising:
generating source code for the big-data application using a template application, wherein the source code comprises a test application, wherein the big-data application comprises a multi-layer container configured to manage the lifecycle of the big data application, and wherein first data that comprises the source code and specific to the big-data application is stored in a different layer in the multi-layer container than second data that is common to a plurality of big-data applications;
building the big-data application using the first data and the second data in one or more build environments generated for the big-data application;
configuring one or more test environments associated with the big-data application, wherein the one or more test environments is configured to assign a server cluster for use by the big-data application;
validating the second data in the big-data application based on testing the big-data application in the one or more test environments;
enabling the source code to be editable by one or more users;
receiving a trigger indicating that the source code has been updated;
in response to receiving the trigger, re-building the big-data application using the updated source code and the second data in the one or more build environments; and
validating the updated source code in the big-data application based on testing the re-built big-data application in the one or more test environments.
|