| CPC E21B 49/00 (2013.01) [G01V 20/00 (2024.01); E21B 2200/22 (2020.05)] | 2 Claims |
|
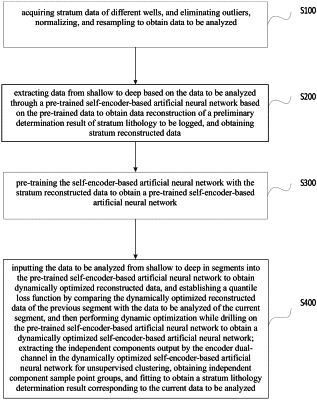
1. A method for extracting features of logging while drilling and drilling-time logging based on Unet dual-channel output, wherein the method comprises:
step S100, acquiring stratum data of different wells, eliminating, outliers, normalizing and resampling to obtain data to be analyzed: wherein the stratum data and the data to he analyzed are 21 curve data of different wells;
wherein the eliminating outliers, normalizing and resampling specifically comprise:
eliminating outliers, analyzing a distribution histogrmn of each straLum data, fitting a Gaussian distribution, and obtaining outliers-eliminated data from, data points out of (u−3σ, u+3σ);
normalizing, based on the eliminated outlier data, normalizing the same eliminated outlier data of different wells end-to-end to obtain normalized data;
 wherein gzs represents a data value of the zth sampling point of the sth curve, and Average represents a calculated average value: gs represents all data sample points of the sth curve; vs represents a variance of the sth curve; czs represents a data value of the zth sampling point of the sth curve after normalization; and
resampling discrete values of different normalized data of different wells into N/W data points using spline interpolation, W being the number of wells:
acquiring pre-trained data;
step S200, performing data reconstruction via a self-encoder-based artificial neural network based on the pre-trained data to obtain stratum reconstructed data;
wherein the self-encoder-based artificial neural network is constructed based on a Unet structure, and comprises an encoder part and a decoder part; the encoder part comprises four convolution layer-pooling layer groups; the number of convolution kernels of the convolution layer successively decreases, the size of the pooling layer is the same as the corresponding convolution layer, and the output end of the encoder is a dual-channel output; the decoder part comprises four deconvolution layers-an up-sampled layer group, wherein the deconvolution layer and the convolution layer in a symmetrical position have the same size but different calculation process, and the size. of the up-sampled layer is the same as that of the corresponding deconvolution layer;
the self-encoder-based artificial neural network is specifically:
the number of channels in the input layer is 21, corresponding to 21 types of curve data, the size of the input layer is 1×N×21, and N is the number of elements:
the convolution layer uses a ReLU function as an activation function output after completing a convolution operation;
4 convolution layers are taken as a first convolution layer, a second convolution layer, a third convolution layer and a fourth convolution layer, and corresponding pooling layers are taken as a first encoder pooling layer, a second encoder pooling layer, a third encoder pooling layer and a fourth encoder pooling layer;
the first convolution layer is a one-dimensional convolution layer with a convolution kernel length of N/(W×K1), K1 is a pre-set value, the number of convolution kernels is 84, the step length is 1, padding=same, and the output size obtained after the first convolution layer is 1×N×84;
the first pooling layer is the maximum pooling layer, the pooling area is 1×2, the step size is 2, the output size is 1×(N/2)×84, and the output channels include 84 channels;
the second convolution layer is a one-dimensional convolution layer with a convolution kernel length of N/(W×K2), K2 is a pre-set value; the number of convolution kernels is 28; the step length is 1; padding=same; the output size obtained after the second convolution layer is 1×(N/2) ×28; and after convolution, a ReLU function is used as an activation function to output;
the second pooling layer is the maximum pooling layer, the pooling area is 1×2, the step size is 2, the output size is 1×(N/4)×28, and the output channels include 28 channels;
the third convolution layer is a one-dimensional convolution layer with a convolution kernel length of N/(W×K3), K3 is a pre-set value, the number of convolution kernels is 7, the step length is 1, padding=same, and the output size obtained after the third convolution layer is 1×(N/4)×7;
the third pooling layer is the maximum pooling layer, the pooling area is 1×2, the step size is 2, the output size is 1×(N/8)×7, and the output channels include 7 channels;
the fourth convolution layer is a one-dimensional convolution layer with a convolution kernel length of N/(W×K4), K4 is a pre-set value, the number of convolution kernels is 2, the step length is 1, padding=same, and the output size obtained after the fourth convolution layer is 1×(N/8)×2;
the fourth pooling layer is the maximum pooling layer, the pooling area is 1×2, the step size is 2, the output size is 1×(N/16)×2, and the output channels include 2 channels;
values of K1, K2, K3 and K4 are set, so that a receptive field of each data point in the dual-channel output of Unet model covers the data point of 1 to 5 m;
the decoder part comprises four deconvolution layers-up-sampled layers, the deconvolution layer has a different calculation process from the convolution layer in a symmetrical position, the size of the up-sampled layer is the same as that of the corresponding deconvolution layer and is calculated using linear interpolation;
the self-encoder-based artificial neural network has a convolution layer calculated by;
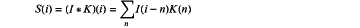 wherein S(i) represents an output value at the position of i, K(n) represents the nth element of the convolution kernel, Σ represents the multiplication and addition of the ith element of the input vector I with the n elements of the convolution kernel; the up-sampled layer is calculated by:
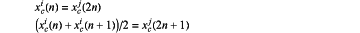 after performing a deconvolution operation on a Lc deconvolution layer, mapping via a ReLU activation function to serve as input data of an up-sampled layer of the Lc layer, and taking an up-sampled output of the Lc layer as input data of a deconvolution layer on the Lc+1 layer;
taking xci as the input data of an up-sampled layer of the Lc layer, taking xcj as an output data of an up-sampled layer of the Lc layer, a vector scale of xcj is twice the xci scale, and c represents a layer sequence number:
step S300: pre-training the self-encoder-based artificial neural network with the stratum reconstructed data to obtain a pre-trained self-encoder-based artificial neural network;
the step S300 specifically comprises:
step S310: calculating a root mean square loss function based on, the stratum reconstructed data:
 wherein xtruei represents the ith data sample of a model input curve, and xpredictioni represents the ith data sample of a model output curve:
step S320: adjusting model parameters by a random batch gradient descent algorithm until the root mean square loss function is lower than a pre-set threshold value, or reaches a pre-set number of iterations, and obtaining a pre-trained self-encoder-based artificial neural network;
step S400: inputting the data to be analyzed from shallow to deep in segments into the pre-trained self-encoder-based artificial neural network to obtain dynamically optimized reconstructed data, and establishing a quantile loss function by comparing the dynamically optimized reconstructed data of the previous segment with the data to be analyzed of the current segment, and then performing dynamic optimization while drilling on the pre-trained self-encoder-based artificial neural network to obtain a dynamically optimized self-encoder-based artificial neural network; extracting the independent components output by the encoder dual-channel in the dynamically optimized self-encoder-based artificial neural network for unsupervised clustering, obtaining independent component sample point groups, and fitting to obtain a stratum lithology determination result corresponding to the current data to be analyzed;
the step s400 specifically comprises:
step S410: guiding a drill according to a pre-set drilling trajectory, and setting an initial momentum gradient to V∇w0=0:
step S420: setting the acquired stratum data as one mini-batch data set when drilling by a preset distance;
step S430: inputting the mini-hatch data set into the self-encoder-based artificial neural network to obtain dynamically optimized reconstructed data;
step S440: calculating a Qraantile Loss quantile loss function and a gradient vector ∇W1 of a weight parameter thereof on the basis of the dynamically optimized reconstructed data;
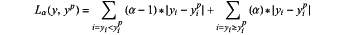 in the formula: y represents the data to be analyzed while drilling, yp represents the reconstructed data corresponding to the first mini-batch data set, and α represents a given quantile, and a value thereof is between 0 and 1;
during drilling, to normalize the historical data together with the currently entered Minibatch data and to calculate the average value of the currently entered Minnibatch data as a value of α:
 in the formula, mn represents a value of the nth sample point in the current minibatch data set, hmin represents the minimum value of historical sample points; and hmax represents the maximum value of historical sample points;
step S450: based on the gradient vector ∇Wk of the kth dataset, performing gradient vector update, and replacing the old gradient vector with a new gradient vector;
V∇wk=βV∇wk−1+(1−β)∇Wk
k represents the serial number of mini-batch data set, and β represents the gradient influence coefficient:
step S460: extracting a dual-channel output of the fourth pooling layer as an independent component:
step S470: based on the independent components. performing clustering via a HAC method, and then fitting via the distribution of a Gaussian mixture model on an axis of the independent components, and using 3σ as a boundary to define a category threshold to obtain independent component sample point groups;
step S480: obtaining a lithologv classification of the current mini-batch data set sample points according to the distribution of core sample points in the independent component sample point groups; and
step S490: repeating the method of steps S430-S480 until all the mini-batch data sets are traversed from shallow to deep to obtain a lithology determination result.
|