| CPC B60W 60/00274 (2020.02) [B60W 30/00 (2013.01); G05D 1/0088 (2013.01); G06F 18/214 (2023.01); G06F 18/41 (2023.01); G06N 3/04 (2013.01); G06N 3/08 (2013.01); G06N 3/084 (2013.01); G06V 10/7784 (2022.01); G06V 20/41 (2022.01); G06V 20/58 (2022.01); G06V 40/20 (2022.01); G08G 1/04 (2013.01); G08G 1/166 (2013.01); G05D 2201/0213 (2013.01); G06N 5/01 (2023.01); G06N 20/10 (2019.01); G06V 10/62 (2022.01)] | 20 Claims |
|
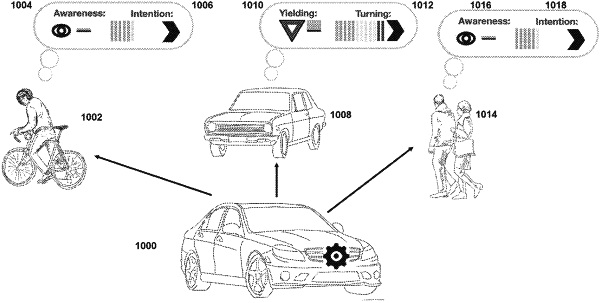
1. A computer-implemented method comprising:
receiving a plurality of training images of an environment, the plurality of training images including one or more persons;
sending the plurality of training images to annotators via a user interface requesting user responses describing an attribute of the one or more persons;
for the plurality of training images, receiving a plurality of user responses from the annotators, each user response describing the attribute of the one or more persons displayed in the plurality of training images;
generating a training dataset comprising summary statistics of the plurality of user responses describing the attribute of the one or more persons displayed in the plurality of training images;
training, using the training dataset, a machine learning based model configured to receive input images and predict summary statistics describing an attribute of one or more persons displayed in the input images;
receiving a plurality of new images of a new environment, the plurality of new images including one or more new persons;
predicting, using the machine learning based model, summary statistics describing an attribute of the one or more new persons in the plurality of new images; and
determining an action to be performed based on the predicted summary statistics of the one or more new persons.
|