| CPC B25J 9/163 (2013.01) [B25J 9/1697 (2013.01); G06F 18/214 (2023.01); G06N 3/08 (2013.01); G06T 7/13 (2017.01); G06T 7/70 (2017.01); G06T 17/00 (2013.01); G06V 10/46 (2022.01); G06V 20/10 (2022.01); G05B 2219/40564 (2013.01)] | 17 Claims |
|
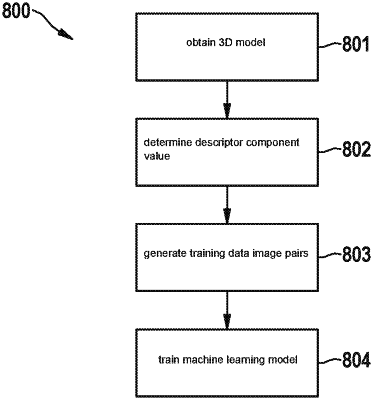
1. A method for training a machine learning model to recognize an object topology of an object from an image of the object, the method comprising the following steps:
obtaining a 3D model of the object, the 3D model encompassing a grid of vertices;
determining a descriptor component value for each vertex of the vertices of the grid;
generating training data image pairs, each training data image pair of the training data image pairs encompassing a training input image showing the object, and a target image, and generating of the target image includes the following:
determining vertex positions of the vertices of the 3D model of the object which the vertices of the 3D model of the object have in the training input image;
assigning, for each determined vertex position in the training input image, the descriptor component value determined for the vertex at the vertex position to the position in the target image; and
adapting at least some of the descriptor component values assigned to the positions in the target image or adding descriptor component values to the positions of the target image, so that descriptor component values that are assigned to positions inside the object and within a predefined spacing from a periphery of the object in the target image become adapted or added in such a way that they are located closer to descriptor component values that are assigned to positions outside the object than to descriptor component values that are assigned to positions in an interior of the object which are located farther than the predefined spacing from the periphery of the object; and
training the machine learning model by monitored learning using the training data image pairs as training data.
|