| CPC H04N 19/86 (2014.11) [G06F 18/214 (2023.01); G06F 18/253 (2023.01); G06N 20/00 (2019.01); H04N 19/117 (2014.11)] | 16 Claims |
|
1. An artifact removal method based on machine learning, performed by an electronic device, the method comprising:
invoking an artifact removal model to perform feature extraction on an ith original image frame of a video, to obtain a feature vector of the ith original image frame, the video comprising at least two original image frames and i being a positive integer;
invoking the artifact removal model to perform dimension reduction on the feature vector, to obtain a feature vector after the dimension reduction;
invoking the artifact removal model to perform feature reconstruction on the feature vector after the dimension reduction, to predict a residual between the ith original image frame and an image frame obtained after the ith original image frame is compressed;
invoking the artifact removal model to add the predicted residual and the ith original image frame, to obtain a target image frame after artifact removal processing; and
sequentially performing encoding and compression on at least two target image frames corresponding to the at least two original image frames, to obtain a video frame sequence after artifact removal,
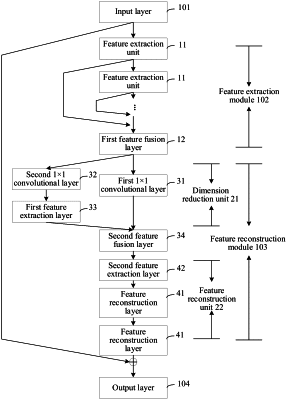
wherein the artifact removal model comprises a first 1×1 convolutional layer, a second 1×1 convolutional layer, a first feature extraction layer, and a feature fusion layer, and
wherein the invoking the artifact removal model to perform the dimension reduction on the feature vector comprises:
invoking the first 1×1 convolutional layer to perform the dimension reduction on the feature vector, to obtain a first feature vector after the dimension reduction;
invoking the second 1×1 convolutional layer to perform the dimension reduction on the feature vector, to obtain a second feature vector after the dimension reduction;
invoking the first feature extraction layer to perform feature extraction on the second feature vector, to obtain a second feature vector after the feature extraction; and
invoking the feature fusion layer to fuse the first feature vector with the second feature vector after the feature extraction, to obtain the feature vector after the dimension reduction.
|