| CPC H04L 65/75 (2022.05) [G06N 3/045 (2023.01); G06N 3/048 (2023.01); G06N 3/08 (2013.01); G10L 19/00 (2013.01); G10L 21/00 (2013.01); H04L 65/403 (2013.01); H04S 3/008 (2013.01); G06N 3/0675 (2013.01); H04S 2400/03 (2013.01); H04S 2400/05 (2013.01); H04S 2420/07 (2013.01)] | 20 Claims |
|
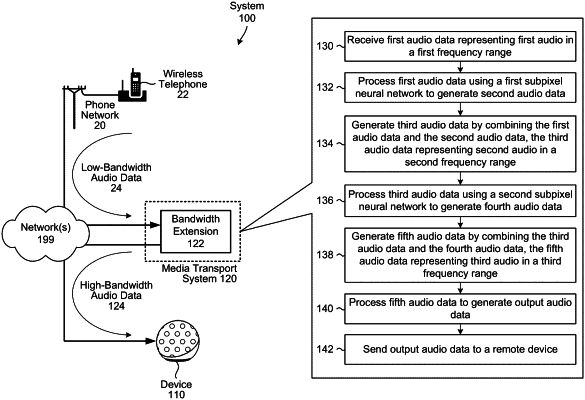
1. A computer-implemented method, the method comprising:
receiving first audio data representing first audio in a first frequency range;
generating, using the first audio data and a first model, second audio data, wherein the first model includes a first plurality of convolutional layers associated with first parameter values;
generating, using the first audio data and the second audio data, third audio data representing second audio in a second frequency range that is larger than the first frequency range and includes the first frequency range;
generating, using the third audio data and a second model, fourth audio data, wherein the second model includes a second plurality of convolutional layers associated with second parameter values that are different than the first parameter values, the first plurality of convolutional layers and the second plurality of convolutional layers having an equal number of layers; and
generating, using the third audio data and the fourth audio data, fifth audio data representing third audio in a third frequency range that is larger than the second frequency range and includes the second frequency range.
|