| CPC G16H 15/00 (2018.01) [G06N 3/08 (2013.01); G16H 30/40 (2018.01)] | 21 Claims |
|
1. A system for processing medical text and associated medical images comprising:
one or more processors; and
memory storing computer-executable instructions that, when executed by the one or more processors, cause the system to perform operations comprising:
training a natural language processor on first training data comprising a first corpus of curated free-text medical reports each of the medical reports having one or more structured labels, to learn to read additional free-text medical reports and produce first structured labels for the additional free-text medical reports;
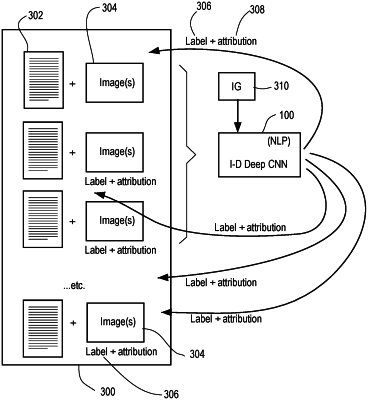
generating second training data based on a second corpus of medical images, each of the medical images of the second corpus having an associated free-text medical report without a structured label, wherein the generating of the second training data comprises applying the trained natural language processor to the associated free-text medical reports of the second corpus to generate second structured labels, and wherein the second training data comprises the medical images of the second corpus and the corresponding second structured labels;
training a computer vision model on the second training data, the computer vision model comprising:
a feature extractor trained to generate a vector of extracted image features for each of the medical images of the second corpus, and
an image classifier trained on the second structured labels and the vectors of extracted image features to predict an output structured label for a further input medical image, wherein the further input medical image is not associated with a medical report; and
providing the trained computer vision model.
|