| CPC G10L 17/08 (2013.01) [G06F 3/167 (2013.01); G06F 21/32 (2013.01); G10L 15/22 (2013.01); G10L 17/02 (2013.01); G10L 17/04 (2013.01); G10L 17/10 (2013.01); G10L 17/14 (2013.01); G10L 17/18 (2013.01); G10L 17/22 (2013.01); G10L 17/24 (2013.01); G10L 2015/088 (2013.01); G10L 2015/227 (2013.01)] | 20 Claims |
|
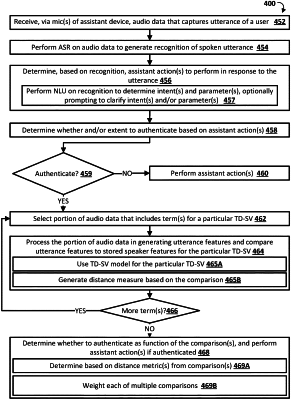
1. A method implemented by one or more processors, the method comprising:
receiving audio data that captures a spoken utterance of a given user, the audio data being detected via one or more microphones of an assistant device of the given user;
processing a first portion of the audio data to generate first utterance features;
performing a first comparison of the first utterance features to first speaker features for a first text dependent speaker verification (TD-SV) for the user, the first TD-SV being dependent on a first set of one or more terms;
processing a second portion of the audio data to generate second utterance features, the second portion of the audio data being distinct from the first portion of the audio data;
performing a second comparison of the second utterance features to second speaker features for a second TD-SV for the user, the second TD-SV being dependent on a second set of one or more terms that are distinct from the first set of one or more terms;
determining, based on both the first comparison and the second comparison, to authenticate the user for the spoken utterance; and
in response to determining to authenticate the user for the spoken utterance:
performing one or more actions, that are based on the spoken utterance.
|