| CPC G10L 15/22 (2013.01) [G01C 21/3608 (2013.01); G06N 20/00 (2019.01); G10L 15/063 (2013.01); G10L 15/065 (2013.01); G10L 15/183 (2013.01)] | 20 Claims |
|
1. An artificial intelligent system of one or more electronic devices for providing an online to offline service in response to a voice request from a user terminal, comprising:
at least one information exchange port of a target system, wherein the target system is associated with a user terminal to receive a voice request from the user terminal through wireless communications between the at least one information exchange port and the user terminal;
at least one storage medium including an operation system and a set of instructions compatible with the operation system for providing an online to offline service in response to a voice request from a user terminal; and
at least one processor in communication with the at least one storage medium, wherein when executing the operation system and the set of instructions, the at least one processor is further directed to:
receive the voice request from the user terminal;
obtain a customized recognition model trained using data associated with a plurality of points of interest associated with the user terminal;
obtain a general recognition model trained using data from general public;
determine a literal destination associated with the voice request based at least on the voice request, the customized recognition model and the general recognition model;
in response to determining the literal destination, generate electronic signals including the literal destination and a triggering code, wherein the triggering code is:
in a format recognizable by an application installed in the user terminal, and
configured to rend the application to generate a presentation of the literal destination on an interface of the user terminal; and
send the electronic signals to the at least one information exchange port of the target system to direct the at least one information exchange port to send the electronic signals to the user terminal, wherein to determine the literal destination associated with the voice request based at least on the voice request, the customized recognition model, and the general recognition model, the at least one processor is directed to:
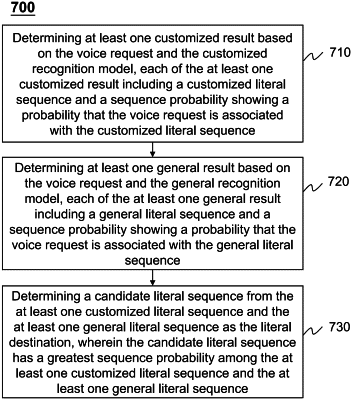
determine at least one customized result based on the voice request and the customized recognition model, each of the at least one customized result including a customized literal sequence and a sequence probability showing a probability that the voice request is associated with the customized literal sequence;
determine a sequence probability of each customized literal sequence by determining a sum of a product of acoustic probabilities corresponding to a plurality of phonemes outputted from an acoustic model and a product of literal probabilities corresponding to a plurality of words outputted from the customized recognition model;
determine at least one general result based on the voice request and the general recognition model, each of the at least one general result including a general literal sequence and a sequence probability showing a probability that the voice request is associated with the general literal sequence;
determine a sequence probability of each general literal sequence by determining a sum of a product of acoustic probabilities corresponding to a plurality of phonemes outputted from the acoustic model and a product of literal probabilities corresponding to a plurality of words outputted from the general recognition model; and
determine the literal destination based on the sequence probability of each customized literal sequence and the sequence probability of each general literal sequence.
|