| CPC G10L 15/20 (2013.01) [G10L 15/02 (2013.01); G10L 15/08 (2013.01); G10L 15/22 (2013.01); G10L 21/0232 (2013.01); G10L 25/84 (2013.01); G10L 2015/025 (2013.01); G10L 2015/088 (2013.01); G10L 2015/223 (2013.01); G10L 2021/02166 (2013.01)] | 17 Claims |
|
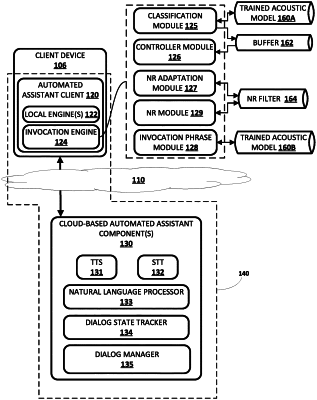
1. A method of detecting an invocation phrase for an automated assistant, the method implemented by one or more processors of a client device and comprising:
for each audio data frame of a first set of sequential audio data frames of a stream of audio data frames that are based on output from one or more microphones of the client device:
generating a corresponding noise reduction filter based on the audio data frame, and
storing the corresponding noise reduction filter in a first in, first out buffer;
for a given audio data frame, of the stream of audio data frames, that immediately follows the first set of sequential audio data frames:
generating a filtered data frame based on processing the given audio frame using the corresponding noise reduction filter that is at a head of the first in, first out buffer,
wherein the corresponding noise reduction filter, that is at the head of the first in, first out buffer, and that is used in generating the filtered data frame, was generated based on an earlier in time audio data frame, of the first set of sequential audio data frames, but not generated based on any more recent in time of the first set of sequential audio data frames, and
determining whether the filtered data frame indicates presence of one or more phonemes of the invocation phrase based on processing the filtered data frame using a trained machine learning model;
determining whether the invocation phrase is present in the stream of audio data frames based on whether the filtered data frame indicates presence of one or more of the phonemes of the invocation phrase.
|