| CPC G08G 5/0043 (2013.01) [G06N 3/084 (2013.01); G08G 5/0026 (2013.01); G08G 5/0039 (2013.01); G08G 5/045 (2013.01)] | 10 Claims |
|
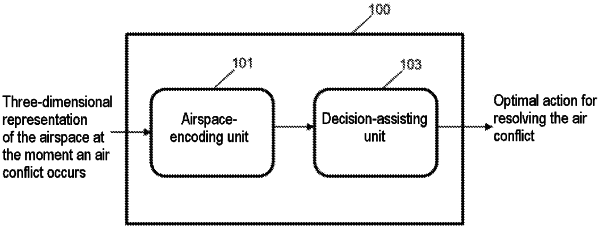
1. A device for managing air traffic, in an airspace comprising a reference aircraft and at least one other aircraft, the device using a three-dimensional representation of the airspace at a time when an air conflict is detected between the reference aircraft and said at least one other aircraft, the device comprising:
an airspace-encoding unit configured to determine a reduced-dimension representation of the airspace by applying a recurrent autoencoder to said three-dimensional representation of the airspace at said air-conflict detection time;
a decision-assisting unit configured to determine a conflict-resolution action to be implemented by said reference aircraft, said decision-assisting unit implementing a deep-reinforcement-learning algorithm to determine said action on the basis of said reduced-dimension representation of the airspace, of information relating to said reference aircraft and/or said at least one other aircraft, and of a geometry corresponding to said air conflict,
and in that said deep-reinforcement-learning algorithm is trained beforehand to approximate a reward function for a given representation of a scenario in the airspace at the time when a conflict is detected, said action corresponding to an optimum strategy that maximizes said reward function in the training phase.
|