| CPC G06T 19/006 (2013.01) [A63F 13/65 (2014.09); G06Q 30/0641 (2013.01); G06T 7/11 (2017.01); G06T 7/20 (2013.01); G06T 7/70 (2017.01); G06T 17/00 (2013.01); G06T 19/20 (2013.01); A63F 2300/69 (2013.01); G06T 2207/10016 (2013.01); G06T 2207/30196 (2013.01); G06T 2219/2004 (2013.01); G06T 2219/2016 (2013.01); G06T 2219/2021 (2013.01)] | 20 Claims |
|
1. A method comprising:
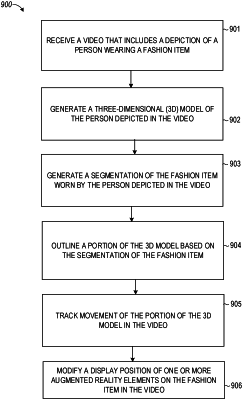
receiving, by one or more processors of a device, a video that includes a depiction of a person wearing a fashion item;
generating, by the one or more processors, a three-dimensional (3D) model of the person depicted in the video;
applying a trained machine learning model to the video that includes the depiction of the person wearing the fashion item, the trained machine learning model extracting one or more features from the video, and the trained machine learning model generating a segmentation of the fashion item worn by the person depicted in the video using the extracted one or more features;
outlining a portion of the 3D model based on the segmentation of the fashion item;
tracking movement of the portion of the 3D model in the video to determine that a portion of the fashion item has been moved towards a particular side;
in response to tracking the movement of the portion of the 3D model in the video, modifying a display position of one or more augmented reality (AR) elements on the fashion item in the video;
in response to determining that the portion of the fashion item has been moved towards the particular side, adjusting an avatar comprising the one or more AR elements;
detecting an emotion associated with the person based on processing voice input associated with the person; and
adjusting a facial expression of the avatar to correspond to the detected emotion associated with the person depicted in the video.
|