| CPC G06Q 10/06313 (2013.01) [G06N 5/022 (2013.01)] | 20 Claims |
|
1. A method, performed by one or more computing devices, for automatically identifying features for training a machine learning model to predict missing attribute values, the method comprising:
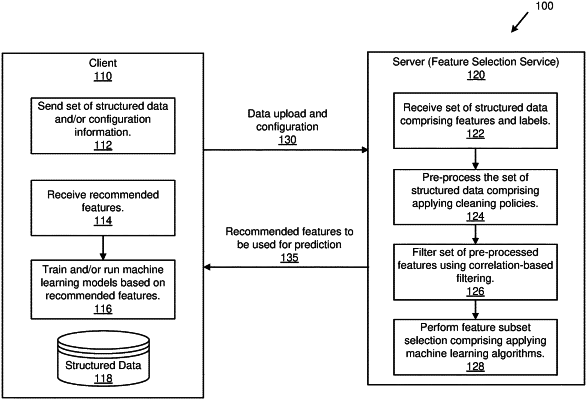
receiving a set of structured data contained in a database table, the structured data comprising a plurality of features, which are identified by at least feature name, feature data type, and feature value; and one or more labels;
pre-processing the set of structured data comprising applying a plurality of cleaning policies, wherein different cleaning policies, of the plurality of cleaning policies, are applied to different feature data types, and wherein the pre-processing produces a set of pre-processed features;
filtering the set of pre-processed features using correlation-based filtering, wherein the correlation-based filtering applies one or more correlation estimation techniques to the set of pre-processed features to remove at least some highly correlated features and produce a set of filtered features;
performing feature subset selection comprising applying one or more supervised machine learning algorithms to the set of filtered features to determine relative importance values among the set of filtered features in relation to the one or more labels, wherein a subset of the set of filtered features is selected based at least in part on the determined relative importance values;
outputting the subset of the set of filtered features; and
training a machine learning model to predict missing attribute values of the one or more labels based on the subset of the set of filtered features,
wherein the correlation-based filtering comprises:
categorizing the plurality of features into multiple feature type groupings based on the feature data type, wherein the multiple feature type groupings comprise a first feature type grouping, a second feature type grouping, and a third feature type grouping, wherein the first feature type grouping contains features having a textural feature data type and a categorical feature data type, wherein the second feature type grouping contains features having a numerical feature data type, wherein the third feature type grouping contains features having a time or date feature data type;
for each feature type grouping, iteratively calculating pairwise correlation measures between pairs of features within the feature type grouping;
for each pair of highly correlated features within each feature type grouping:
determining which feature, of the pair of features, has more populated feature values existing in a column of the database table corresponding to the feature;
retaining the feature that has more populated feature values; and
filtering out the other feature of the pair of features.
|