| CPC G06N 5/04 (2013.01) [G06N 20/00 (2019.01)] | 20 Claims |
|
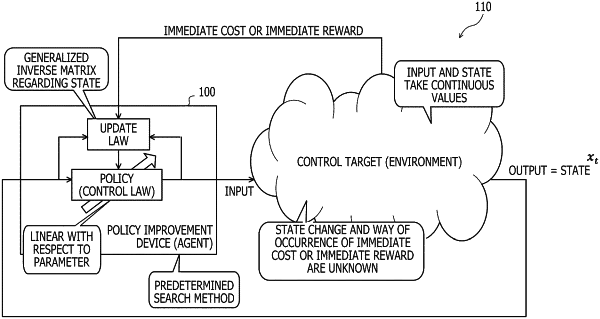
1. A policy improvement method of improving a policy of reinforcement learning based on a state value function, the policy improvement method causing a computer to execute a process comprising:
calculating an input to a control target based on the policy and a predetermined exploration method of exploring for an input to the control target in the reinforcement learning; and
updating a parameter of the policy based on a result of applying the calculated input to the control target, using the input to the control target and a generalized inverse matrix regarding a state of the control target, wherein the computer executes the process multiple times including:
calculating the input to the control target based on the policy and the exploration method;
estimating the state value function;
calculating a TD (Temporal Difference) error based on the result of applying the calculated input to the control target and a result of estimating the state value; and
determining whether or not to use the input to update the parameter of the policy based on the result of applying the calculated input to the control target including, based on the calculated TD error,
determining to use the input if it is determined that a preferable effect has been obtained with the input, and
determining not to use the input if it is determined that a preferable effect is not obtained with the input, based on the calculated TD error,
if it is determined that the input is used, recording the input;
if it is determined that the input is not used, recording a different input to the control target calculated from the policy; and
recording the state of the control target when the input is calculated; and
wherein in updating,
updates the parameter of the policy using inputs to the control target recorded multiple times and a generalized inverse matrix regarding states of the control target recorded multiple times so that there appears a tendency to output an input to the control target determined to have obtained a preferable effect and not to output an input to the control target determined to not have obtained a preferable effect.
|