| CPC G06N 3/08 (2013.01) [G06F 7/575 (2013.01)] | 20 Claims |
|
1. A method of generating a neural network structure including one or more input layers each associated with one or more filters, the method comprising:
determining, for an architecture of a device, a bit length of a set of registers of the device used to perform arithmetic operations;
determining a first integer representation for the one or more input layers and a second integer representation for the one or more filters, the first integer representation associated with a first range of integer values and the second integer representation associated with a second range of integer values;
generating dimensionalities of the one or more input layers and the one or more filters, the dimensionalities determined such that an output value generated by combining elements of an input layer as maximum values of the first integer representation with elements of a corresponding filter as maximum values of the second integer representation does not overflow the bit length of the registers; and
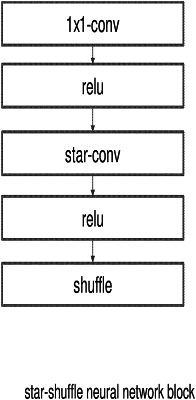
generating the neural network structure with the determined dimensionalities, wherein for each individual layer which forms the neural network structure, activations are quantized using activation parameters for the individual layer and the weights are quantized using layer parameters for the individual layer, wherein the activations and the activation parameters are provided as input to the individual layer, and wherein quantized output associated with the individual layer is dequantized using (1) the input activation parameters and (2) the layer parameters.
|