| CPC G06F 9/505 (2013.01) [G06F 9/3877 (2013.01); G06F 9/3891 (2013.01); G06F 9/5038 (2013.01); G06F 30/331 (2020.01)] | 20 Claims |
|
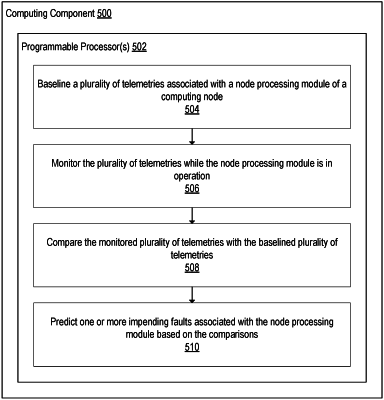
1. A method for hardware-based predictive fault detection and analysis, the method comprising:
baselining, by processing logic components of a computing cluster with a plurality of processing nodes, a first plurality of telemetries associated with at least one processing node, wherein the telemetries include temperatures, voltages, and currents of processing resources associated with a respective processing node, and wherein the processing resources comprise hardware components including at least a voltage regulator;
monitoring, by the processing logic components, the first plurality of telemetries continuously while the at least one processing node is executing computing tasks;
monitoring, by the processing logic components, other pluralities of the telemetries of other processing nodes while the other processing nodes are in operation, wherein monitoring a respective plurality of the telemetries comprises monitoring errors associated with at least one of:
input/output (I/O) buses and buses of a respective processing node;
a peripheral component interconnect express (PCIe) interface of the respective processing node;
a memory data interface of the respective processing node; and
a high-speed data or network interface of the respective processing node;
comparing, by the management logic components, the monitored first plurality of telemetries associated with the at least one processing node with the monitored other pluralities of telemetries of the other processing nodes;
predicting one or more impending faults associated with the at least one processing node based on the comparing the monitored first plurality of telemetries with the baselined first plurality of telemetries and the comparing the monitored first plurality of telemetries associated the at least one processing node with the monitored other pluralities of telemetries of the other processing nodes; and
in response to predicting the one or more impending faults associated with the at least one processing node, preemptively allocating, by the management logic components autonomously and without administrative intervention, computing tasks assigned to the at least one processing node predicted to have one or more impending faults to the other processing nodes that are performed by the other processing nodes.
|