| CPC G06F 40/30 (2020.01) [G06F 40/166 (2020.01); G06F 40/40 (2020.01); G06N 3/08 (2013.01); G06F 40/242 (2020.01); G06F 40/284 (2020.01)] | 20 Claims |
|
1. A method comprising:
generating a set of sentences based on a document;
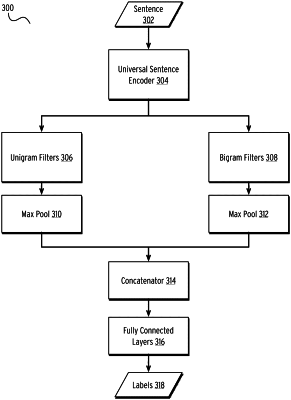
predicting a set of labels for each sentence using a multi-label classifier, the multi-label classifier including a self-attended contextual word embedding backbone layer, a bank of trainable unigram convolutions, a bank of trainable bigram convolutions, and a fully connected layer, the multi-label classifier trained using a weakly labeled data set; and
labeling the document based on the set of labels.
|