| CPC G06F 18/2115 (2023.01) [G06F 18/2148 (2023.01); G06F 18/2431 (2023.01); G06V 10/764 (2022.01); G06V 40/172 (2022.01)] | 20 Claims |
|
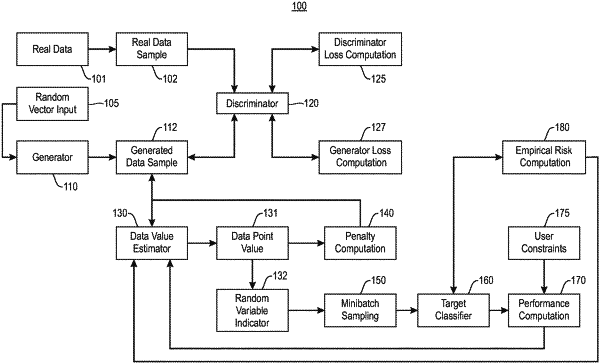
1. A computer program product comprising a computer readable storage medium having program instructions embodied therewith, the program instructions executable by one or more processors to cause the one or more processors to:
generate, using a first machine learning model, one or more synthetic data instances for training a target machine learning classifier;
input the one or more synthetic data instances to a neural network, wherein the neural network classifies whether respective ones of the one or more synthetic data instances are one of a synthetic data instance and a real data instance;
identify whether the classifications of the respective ones the one or more synthetic data instances are correct;
evaluate the classifications of the respective ones of the one or more synthetic data instances using a first loss function and a second loss function;
update weights applied in a learning algorithm used by the neural network based on an output of the first loss function;
train the first machine learning model based at least in part on whether the classifications of the respective ones of the one or more synthetic data instances are correct, wherein in training the first machine learning model, the program instructions cause the one or more processors to update weights applied in a learning algorithm used by the first machine learning model based on an output of the second loss function;
determine, using a second machine learning model, values of respective ones of the one or more synthetic data instances with respect to at least one task; and
generate a subset of the one or more synthetic data instances for use in the training of the target machine learning classifier, wherein the generation of the subset is based at least in part on the values of respective ones of the one or more synthetic data instances with respect to the at least one task.
|