| CPC G06F 16/2379 (2019.01) [G06N 20/00 (2019.01)] | 20 Claims |
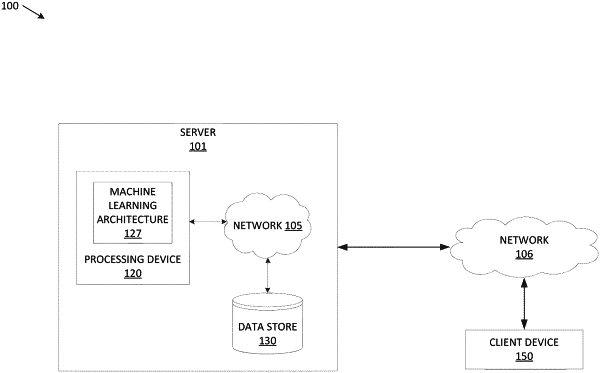
|
1. A method, comprising:
inputting a testing set comprising a plurality of input data samples into each one of a plurality of pre-trained machine learning models to generate a set of embeddings output by the plurality of pre-trained machine learning models; and
performing, by a processing device, N iterations of a cluster labeling algorithm, wherein each iteration comprises:
generating a plurality of clusterings from the set of embeddings;
analyzing the plurality of clusterings to identify a target embedding with a highest cluster quality among the set of embeddings;
analyzing the target embedding to determine a compactness for each of the plurality of clusterings of the target embedding;
identifying a target cluster among the plurality of clusterings of the target embedding based on the compactness, wherein a subset of the plurality of input data samples are members of the target cluster; and
assigning pseudo-labels to the subset of the plurality of input data samples and removing the subset from the testing set for all embeddings.
|