| CPC G06F 11/1662 (2013.01) [G06F 3/0622 (2013.01); G06F 3/064 (2013.01); G06F 3/0679 (2013.01); G06F 11/1088 (2013.01); G06F 11/3034 (2013.01); G06F 16/27 (2019.01)] | 47 Claims |
|
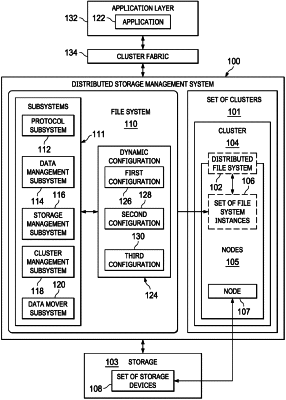
1. A non-transitory machine readable medium storing instructions, which when executed by a processing resource of a first node of a plurality of nodes of a cluster of a distributed storage management system, cause the first node to:
identify a failed Redundant Array of Independent Disks (RAID) stripe, wherein availability of data blocks is supported by way of a redundancy scheme implemented by the cluster;
identify, by a key-value (KV) store of the first node, a plurality of block identifiers (IDs) associated with the failed RAID stripe, wherein the KV store contains data blocks as values and their respective block IDs as keys; and
for each block identifier (ID) of the plurality of block IDs, restore a data block corresponding to the block ID by:
reading the data block from a node of the plurality of nodes having a redundant copy of the data block; and
writing the redundant copy of the data block to a storage area of the first node that is unaffected by the failed RAID stripe.
|