| CPC G06F 16/353 (2019.01) [G06F 16/38 (2019.01); G06F 40/166 (2020.01); G06F 40/279 (2020.01)] | 19 Claims |
|
1. A method comprising:
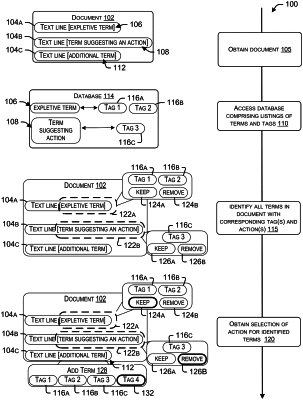
obtaining, at a term auto-tagging system, a document from a client device;
identifying, by the term auto-tagging system, a series of text portions in the document;
processing, by a machine learning model of the term auto-tagging system, each of the series of text portions to:
identify a first set of terms in the document associated with a first tag of a plurality of tags by comparing each of the series of text portions with a database mapping terms with the plurality of tags, each tag uniquely specifying a class of terms;
associate each of the first set of terms with the first tag of the plurality of tags;
identify a second set of terms in the document associated with a second tag of the plurality of tags maintained at the database using metadata maintained at the database; and
associate each term of the second set of terms with the one or more identified tags;
providing, by the term auto-tagging system, a first visual representation to the client device, the first visual representation identifying each of the first set of terms and the second set of terms, each tag corresponding with each of the first set of terms and the second set of terms, and one or more actions for each of the first set of terms and the second set of terms;
responsive to obtaining selections of the one or more actions for any of the identified terms, generating, by the term auto-tagging system, a second visual representation that modifies the first visual representation according to the obtained selections of the one or more actions for any of the identified terms;
for each identified term, providing, by the term auto-tagging system to the database, new metadata for tags associated with each term, the new metadata comprising the term, the one or more tags associated with the term, text for the text portion corresponding with the term, and an indication of any selection of any action for the term; and
responsive to obtaining the selections of the one or more actions for any of the identified terms, training the machine learning model using the new metadata; and
providing the second visual representation to the client device.
|