| CPC G06F 16/3334 (2019.01) [G06F 16/313 (2019.01); G06F 16/35 (2019.01); G06N 3/044 (2023.01)] | 14 Claims |
|
1. A method for processing textual data, the method comprising:
receiving the textual data from one or more documents;
analyzing the textual data including:
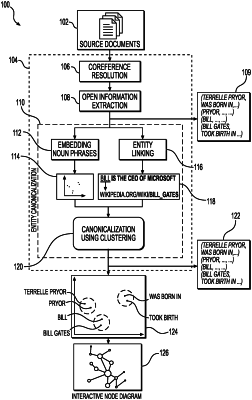
performing coreference resolution on the textual data to determine a single term for all of a number of entity mentions in the textual data that reference a same entity, wherein the coreference resolution is performed in such manner for each of a plurality of different entities in the textual data to produce a plurality of single terms, each of which corresponds to a respective entity of the plurality of different entities;
performing open information extraction (OIE) based on each of the plurality of single terms generated by the coreference resolution to, in turn, generate one or more triplet representations of the textual data using one or more of first, second, and third OIE models, wherein each of the one or more triplet representations is associated with an entity and includes a subject, predicate, and object;
linking noun phrases of one or more of the plurality of different entities to external sources to achieve one or more respective linked entities;
performing canonicalization of the one or more triplet representations using, in part, hierarchical agglomerative clustering (HAC) to identify one or more entity clusters based on each associated entity and the one or more linked entities, and to determine one or more canonicalized triplet representations, wherein performing canonicalization further comprises selecting a representative entity name for all subjects and objects that refer to the same entity; and replacing all entity name forms in the entity cluster with the representative entity name; and
mapping the one or more triplet representations into a structured knowledge graph, storing the structured knowledge graph in at least one memory device, based on the one or more canonicalized triplet representations for display in a graphical user interface, the structured knowledge graph comprising a plurality of nodes and connections between each of the plurality of nodes, wherein each node represents one of the subject or object of a canonicalized triplet representation of the one or more canonicalized triplet representations, and each connection represents a predicate of a canonicalized triplet representation of the one or more canonicalized triplet representations.
|