| CPC G10L 15/16 (2013.01) | 20 Claims |
|
1. A method comprising:
receiving a plurality of audio frames representing audio captured by a device;
determining a first subset of the plurality of audio frames;
determining a second subset of the plurality of audio frames, wherein the second subset is different from the first subset but includes at least one audio frame from the first subset;
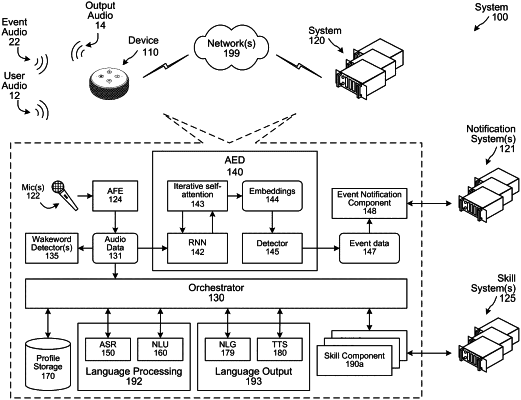
processing, using a convolutional recurrent neural network encoder (CRNN) configured to determine audio features in the plurality of audio frames, the first subset to generate first hidden state data of the CRNN;
determining preliminary embedding data using at least the first hidden state data;
processing, using the CRNN, the second subset and the first hidden state data to generate second hidden state data of the CRNN;
determining interim embedding data using the second hidden state data and the preliminary embedding data;
determining, using at least the interim embedding data, final embedding data representing audio features representing the audio;
processing the final embedding data with respect to stored data to determine results data, the stored data representing audio of an event; and
determining, based at least in part on the results data, that an instance of the event has occurred.
|
|
5. A method comprising:
receiving a first portion of audio data;
receiving a second portion of audio data;
processing, using a recurrent neural network (RNN), the first portion of audio data to generate first data representing a first hidden state of the RNN;
processing the first data to determining a first variable value;
determining second data representing a first embedding using at least the first data;
processing, using the RNN, the second portion of audio data and the first data to generate third data representing a second hidden state of the RNN;
determining, using the third data, a second variable value;
determining fourth data representing a second embedding using the third data, and the first embedding; and
determining, using at least the fourth data and the second variable value, fifth data representing audio features representing the audio data.
|
|
13. A system, comprising:
at least one processor; and
at least one memory comprising instructions that, when executed by the at least one processor, cause the system to:
receive a first portion of audio data;
receive a second portion of audio data;
process, using a recurrent neural network (RNN), a first portion of audio data to generate first data representing a first hidden state of the RNN;
process the first data to determining a first variable value;
determine second data representing a first embedding using at least the first data;
process, using the RNN, the second portion of audio data and the first data to generate third data representing a second hidden state of the RNN;
determine, using the third data, a second variable value;
determine fourth data representing a second embedding using the third data and the first embedding; and
determine, using at least the fourth data and the second variable value, fifth data representing audio features representing the audio data.
|