| CPC G06F 9/5027 (2013.01) [G06F 8/65 (2013.01); G06F 9/45558 (2013.01); G06N 5/046 (2013.01); G06N 20/00 (2019.01); G06T 1/20 (2013.01); G06F 2009/4557 (2013.01); G06F 2009/45583 (2013.01); G06F 2009/45595 (2013.01)] | 20 Claims |
|
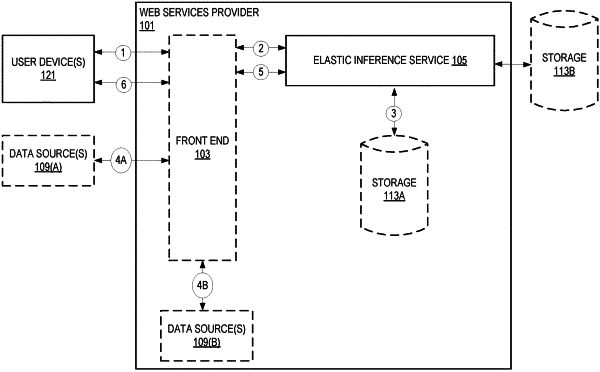
1. A computer-implemented method, comprising:
attaching a first set of one or more graphical processing unit (GPU) slots of an accelerator appliance to an application instance according to an application instance configuration, the attached application instance remote from the accelerator appliance in a multi-tenant provider network, the accelerator appliance comprising a plurality of GPUs, the plurality of GPUs having a compute capacity, each GPU slot of the first set of one or more GPU slots corresponding to a fraction of the compute capacity of the plurality of GPUs;
loading a machine learning model of the attached application instance onto the first set of one or more GPU slots;
handling a first set of one or more inference calls, made by an application of the attached application instance to the loaded machine learning model, using the first set of one or more GPU slots;
detecting a response timing related to handling the first set of inference calls using the first set of one or more GPU slots;
based on determining that the first set of one or more GPU slots no longer meet at least one of a timing requirement or a cost requirement, migrating processing for the attached application instance from the first set of one or more GPU slots to a second set of one or more GPU slots including detaching the first set of one or more GPU slots from the application instance, attaching the second set of one or more GPU slots to the application instance, and loading the machine learning model of the attached application instance onto the second set of one or more GPU slots;
handling a second set of one or more inference calls, made by the application of the attached application instance to the loaded machine learning model, using the second set of one or more GPU slots; and
returning, to the application of the application instance, a result of the second set of one or more inference calls.
|