| CPC G06F 40/30 (2020.01) [G06N 20/00 (2019.01); G06V 10/25 (2022.01); G06V 10/764 (2022.01); G06V 10/82 (2022.01); G06F 18/217 (2023.01); G06F 40/205 (2020.01)] | 17 Claims |
|
1. A method of training a machine learning model, comprising:
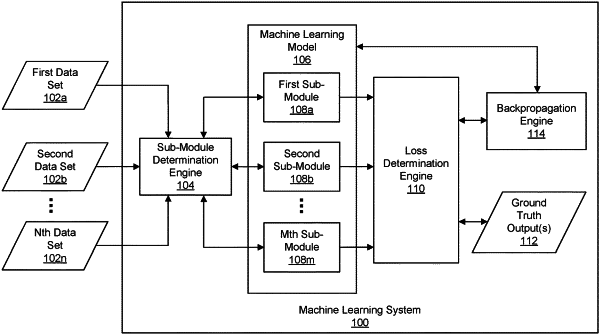
generating a neural network model to perform a referring expression task based on a plurality of training datasets, wherein each training dataset includes data of a different data format, wherein the neural network model includes an image classification sub-module configured to perform an image classification task and a phrase parsing sub-module configured to perform a phrase parsing task, wherein the image classification task and phrase parsing task are combined to obtain the referring expression task of the neural network model;
receiving the plurality of training datasets, wherein the plurality of training datasets comprises a first training dataset comprising images and a second training dataset comprising natural language phrases, wherein the first training dataset is an image classification dataset, and wherein the second training dataset is a natural language dataset;
determining a data format associated with the first training dataset is an image format;
identifying, using a lookup table, the image classification sub-module as being associated with the image format;
training the image classification sub-module using the images of the image classification dataset, wherein the image classification sub-module is trained to perform the image classification task;
determining a data format associated with the second training dataset is a text format identifying, using the lookup table, the phrase parsing sub-module as being associated with the text format; and
training the phrase parsing sub-module using the natural language phrases of the natural language dataset, wherein the phrase parsing sub-module is trained to perform the phrase parsing task.
|