| CPC G06F 17/16 (2013.01) [G06F 17/141 (2013.01); G06N 3/045 (2023.01); G06N 3/063 (2013.01)] | 20 Claims |
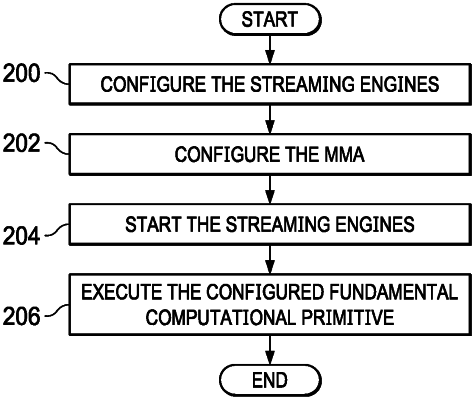
|
1. A matrix multiplication accelerator comprising:
a first formatting component having a first input and a first output;
a second formatting component having a second input and second output;
a third formatting component having a third input and a third output;
a row offset component having an offset input coupled to the second output, and an offset output;
a first memory having a first matrix input coupled to the first output, and a first matrix output;
a second memory having a second matrix input coupled to the offset output, and a second matrix output;
a nonlinearity component having a nonlinearity input, and a nonlinearity output coupled to the third input;
a third memory having a third matrix input, and a third matrix output coupled to the nonlinearity input; and
a matrix multiplication component coupled to the first matrix output, the second matrix output, and the third matrix input.
|