| CPC G06F 16/35 (2019.01) [G06F 16/313 (2019.01)] | 6 Claims |
|
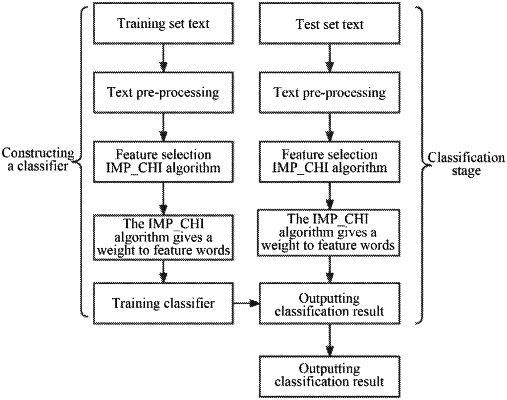
1. A text classification method based on feature selection, comprising:
acquiring a text classification data set;
dividing the text classification data set into a training text set and a test text set, and then pre-processing the training text set and the test text set;
extracting feature entries from the pre-processed training text set through an improved chi-square (IMP_CHI) statistical formula to form feature subsets;
using a Term Frequency-Inverse Word Frequency (TF-IWF) algorithm to give weights to the extracted feature entries;
based on the weighted feature entries, establishing a short text classification model based on a support vector machine; and
classifying the pre-processed test text set by the short text classification model;
wherein the pre-processing comprises first performing standard processing including removing stop words on a text, and then selecting Jieba word segmentation tool to segment the processed short text content to obtain the training text set and the test text set which have been segmented, and storing the training text set and the test text set in a text database;
wherein extracting the feature entries from the pre-processed training text set through the improved chi-square statistical formula to form feature subsets comprises:
extracting each feature word t and its related category information from the text database;
calculating a word frequency adjustment parameter α(t,ci), an intra-category position parameter β and a negative correlation correction factor γ of the feature word t with respect to each category;
using an improved formula to calculate an IMP_CHI value of an entry with respect to each category;
according to the improved chi-square statistics statistical formula, obtaining an IMP_CHI value of a feature word t with respect to the whole training text set; and
after calculating IMP_CHI values of the whole training text set, selecting first M words as features represented by a document to form a final feature subset according to descending orders of the IMP_CHI values.
|