| CPC G05D 1/0221 (2013.01) [G05D 1/0214 (2013.01); B25J 9/163 (2013.01); B25J 9/1664 (2013.01); G05D 1/0274 (2013.01)] | 10 Claims |
|
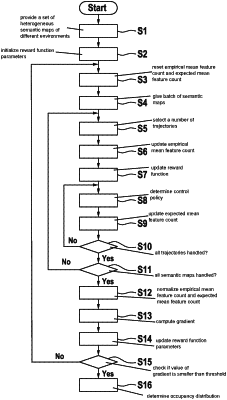
1. A computer-implemented method for determining a motion trajectory for a mobile robot based on occupancy priors indicating probabilities of presence of dynamic objects and/or individuals in a map of an environment, wherein the occupancy priors are determined by a reward function defined by reward function parameters, the determining of the reward function parameters comprising the following steps:
providing a number of semantic maps;
providing a number of training trajectories for each of the number of semantic maps;
computing a gradient as a difference between an expected mean feature count and an empirical mean feature count depending on each of the number of semantic maps and on each of the number of training trajectories, wherein the empirical mean feature count is a first sum of averages, each of the averages of the first sum being an average number of features accumulated over the provided training trajectories of a different semantic map of a plurality of the semantic maps, and wherein the expected mean feature count is a second sum of averages, each of the averages of the second sum being an average number of features accumulated by trajectories generated, depending on current reward function parameters, for a different semantic map of the plurality of semantic maps; and
updating the reward function parameters depending on the gradient.
|