| CPC H04N 19/90 (2014.11) [H04N 19/176 (2014.11); H04N 19/865 (2014.11)] | 20 Claims |
|
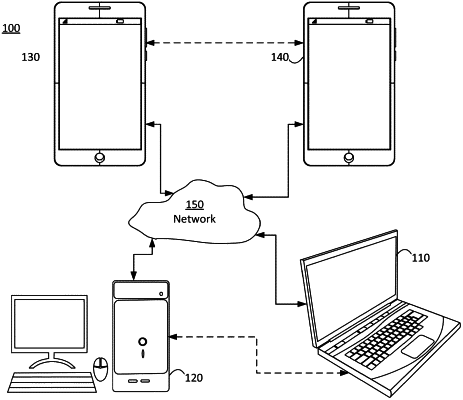
1. A method of encoding a video stream using video point cloud coding, the method being performed by at least one processor and comprising:
obtaining an input point cloud;
dividing the input point cloud into a plurality of chunks, including a first chunk comprising a first plurality of points and a second chunk comprising a second plurality of points, based on determining that the chunks are aligned with an axis of a bounding box of the input point cloud, the first plurality of points being a first sub-point cloud of the input point cloud, and the second plurality of points being a second sub-point cloud of the input point cloud;
applying a patch generation process to the first chunk to generate a first plurality of patches based on the first plurality of points;
applying the patch generation process separately to the second chunk to generate a second plurality of patches based on the second plurality of points, wherein the second plurality of patches is different from the first plurality of patches;
packing the first plurality of patches and the second plurality of patches;
generating at least one texture image based on the packed first plurality of patches and the packed second plurality of patches;
generating at least one geometry image based on the packed first plurality of patches and the packed second plurality of patches; and
generating the video stream based on the at least one texture image and the at least one geometry image,
wherein dividing the input point cloud into the plurality of chunks comprises:
determining eigen vectors, of at least Φ={ϕ1, ϕ2, ϕ3}, by estimating a covariance matrix of the input point cloud with N points according to at least
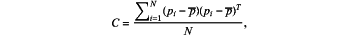 where p denote a centroid of the point cloud determined according to at least
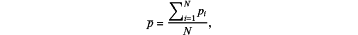 and wherein the eigen vectors and eigen values, of at least Λ={λ1, λ2, λ3)}, are determined by decomposition of C according to at least
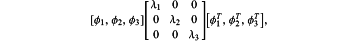 where superscriptT denotes transpose;
setting the eigen vectors and eigen values in descending order of at least λ1>λ2>λ3, wherein unit vectors of the input point cloud are denoted by x=(1, 0, 0), y=(0, 1, 0), z=(0, 0, 1); and
performing chucking along the axis, denoted as v*, and whose inner product with ϕ1 has a largest absolute value, according to at least
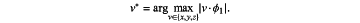 |