| CPC G10L 15/26 (2013.01) [G06F 3/167 (2013.01)] | 20 Claims |
|
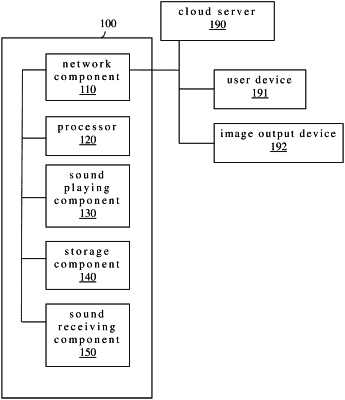
1. A smart speaker, comprising:
a network component;
a processor configured to preload linked settings among voiceprint data of a plurality of registered users, user information of each of the registered users and authority settings corresponding to a plurality of registered display devices from a storage component, wherein the plurality of registered display devices are not part of the smart speaker, and the plurality of registered display devices comprises a user device corresponding to one of the registered users and an image output device;
a sound playing component electrically connected to the processor; and
a sound receiving component configured to receive a voice;
wherein the processor is configured to convert the received voice into a voice text, recognize a voiceprint of the received voice among the voiceprint data of the registered users, identify the specific user information of the one of the registered users corresponding to the recognized voiceprint, and transmit the specific user information and the voice text to a cloud server through the network component, wherein the voice text does not indicate any of the registered display devices and the network component is configured to receive a response message in response to the voice text from the cloud server and the processor is configured to determine whether to send at least part of the response message to one of the registered display devices through the network component based on the linked settings and a privacy tag or a content rating tag of the response message;
wherein the authority settings corresponding to the registered display devices include a plurality of cast settings corresponding to the registered display devices respectively, wherein the authority settings and cast settings corresponding to the image output device comprise a plurality of content rating or privacy setting to restrict the response message with privacy tag or the content rating tag to be displayed on the image output device,
wherein the smart speaker generates a synthesized voice reply message and a data reply message according to content of the response message, if the synthesized voice reply message or the data reply message includes the privacy tag, the processor determines the synthesized voice reply message not to be played by the sound playing component, the processor determines to push the data reply message only to the user device corresponding to the one of the registered users through the network component, and the processor determines not to push the data reply message to the image output device through the network component, and
if the synthesized voice reply message or the data reply message does not include the privacy tag, the processor determines the synthesized voice reply message be played by the sound playing component.
|