| CPC G09B 19/04 (2013.01) [G06N 3/08 (2013.01); G10L 15/22 (2013.01); G10L 17/02 (2013.01); G10L 17/18 (2013.01); G10L 2015/227 (2013.01); G10L 2015/228 (2013.01)] | 9 Claims |
|
7. A computer system comprising:
one or more computer processors;
one or more computer readable storage media; and
program instructions stored on the computer readable storage media for execution by at least one of the one or more processors, the program instructions comprising:
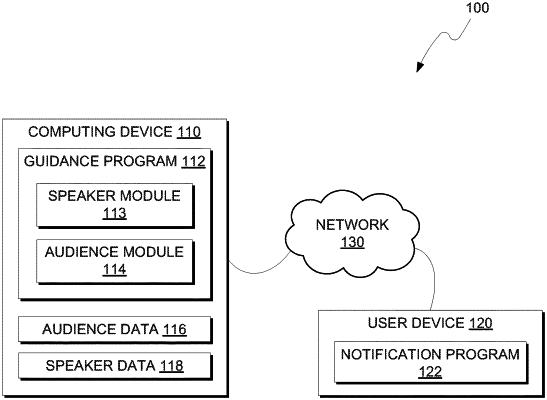
program instructions to retrieve speaker data regarding a speech made by a user;
program instructions to separate the speaker data into one or more speaker modalities;
program instructions to extract one or more speaker features from the speaker data for the one or more speaker modalities;
program instructions to extract one or more audience features from audience data gathered in association with the speech made by the user;
program instructions to generate an audience classification of the one or more audience features;
program instructions to generate a first performance classification based on a multimodal deep-learning neural network, wherein each of the one or more speaker modalities and each of the one or more audience features are connected to a respective input layer of a respective neural network for the multimodal deep-learning neural network;
in response to the first performance classification indicating positive performance by the user while at least one of the one or more audience features indicating negative performance by the user, program instructions to retrain the multimodal deep-learning neural network with the one or more audience features indicating negative performance by the user; and
program instructions to generate a second performance classification regarding a second speech based on the retrained multimodal deep-learning neural network.
|