| CPC G06N 3/063 (2013.01) [G06F 9/3887 (2013.01); G06F 9/3891 (2013.01); G06F 9/5027 (2013.01); G06N 3/084 (2013.01); G06N 5/046 (2013.01)] | 18 Claims |
|
1. A system for machine learning acceleration, comprising:
a plurality of tensor processor clusters, each comprising:
a plurality of tensor processors; and
a cluster-level controller configured to:
receive a multi-cycle instruction, wherein each of the plurality of tensor processor clusters receives a respective multi-cycle instruction, and wherein the respective multi-cycle instructions are distributed across the plurality of tensor processor clusters in accordance with single-program-multiple-data (SPMD) parallelism such that at least two of the plurality of tensor processor clusters receive and execute different multi-cycle instructions while operating on an input feature map;
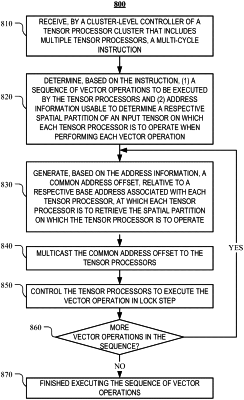
determine, based on the multi-cycle instruction, (1) a sequence of vector operations to be executed by the tensor processors and (2) address information usable to determine a respective spatial partition of an input tensor on which each tensor processor is to operate when performing each vector operation; and
for each vector operation in the sequence:
generate, based on the address information, a common address offset, relative to a respective base address associated with each tensor processor, at which each tensor processor is to retrieve the respective spatial partition of the input tensor on which the tensor processor is to operate;
multicast the common address offset to the tensor processors; and
control the tensor processors to execute the vector operation in lock step.
|