| CPC G06F 9/4893 (2013.01) [G06N 3/045 (2023.01)] | 12 Claims |
|
1. A method comprising:
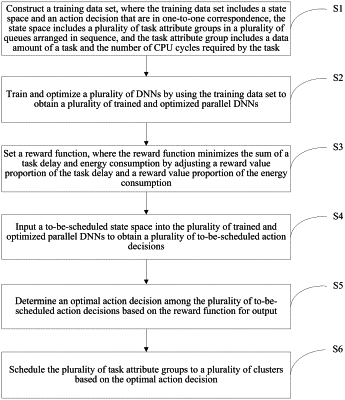
step S1: training and optimizing a plurality of parallel deep neural networks (DNN) by using a training data set to obtain a plurality of trained and optimized parallel DNNs, wherein the training data set comprises training state spaces and training action decisions that are in one-to-one correspondence, each training state space comprises a plurality of attribute groups in a plurality of queues arranged in sequence for a task, and each attribute group comprises a data amount of the task and a number of CPU cycles required by the task;
step S2: inputting a target state space into the plurality of trained and optimized parallel DNNs to obtain a plurality of target action decisions; and
step S3: storing the target state space and an optimal action decision as a sample in a replay memory, wherein the optimal action decision is based on a reward function and is one of the plurality of target action decisions, and wherein the reward function adjusts a reward value proportion of a task delay and a reward value proportion of energy consumed to minimize a sum of the task delay and the energy consumed, wherein the energy consumed is an amount of energy consumed by a computation process of the task and a transmission process of the task, wherein the task delay is an amount of time consumed by the computation process and the transmission process, wherein a plurality of task attribute groups in the target state space is scheduled on a plurality of computer clusters based on the optimal action decision, and wherein steps S2 and S3 are repeatedly performed until a number of samples in the replay memory reaches a threshold.
|