| CPC G06F 40/30 (2020.01) [G06F 3/04847 (2013.01); G06F 18/2178 (2023.01); G06F 18/2193 (2023.01); G06F 18/231 (2023.01); G06F 40/284 (2020.01); G06N 7/02 (2013.01)] | 20 Claims |
|
1. A system for generating a graphical user-interface based dashboard based on a set of received textual input data objects, the system comprising:
a computer memory operating in conjunction with a data storage;
a computer processor configured to:
receive the textual input data objects, each textual input data object representing an incident ticket having at least a first brief description textual field and a second long description textual field;
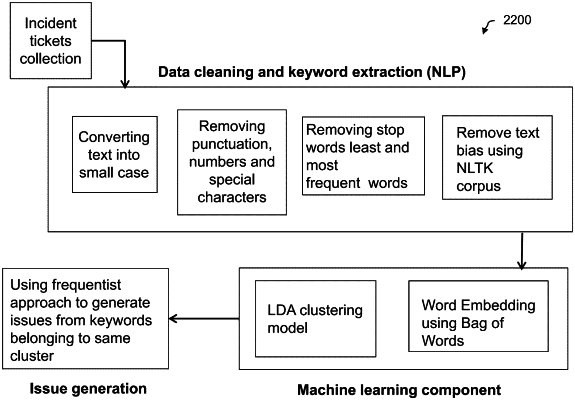
pre-process the textual input data objects to tokenize the textual input data objects into individual words and to remove stop words and punctuation;
apply a first level of clustering of the textual input data objects by processing the first brief description textual field of the textual input data objects using an unsupervised Latent Dirichlet Allocation (LDA) topic model that generates a number of first level classifications based on automatically identified clusters, generates a set of probabilistic outputs indicative of a probability of membership for each of the textual input data objects in each of the automatically identified clusters, and assigns each of the textual input data objects to a corresponding automatically first level classification based on a highest probability of membership in the set of probabilistic outputs;
apply a second level of clustering of the second long description textual field of the textual input data objects by processing the textual input data objects using a hierarchical clustering approach having a dynamically defined number of second-level clusters;
label each cluster of the dynamically defined number of second-level clusters based on one or more identified topics of clusters that are identified by applying weights based on coherence measures obtained from the LDA topic model on individual words of the textual input data objects of the cluster being labelled; and
control rendering of (i) an output dashboard interface rendering an interactive visual graphical object based on the first level of clustering, the second level of clustering, and the labels of the second-level clusters, and (ii) an interactive visual control having a visual element controllable to modify the dynamically defined number of second-level clusters such that when a modification of the dynamically defined number of second-level clusters is triggered, the second level of clustering is re-applied and the output dashboard is re-rendered.
|