| CPC G06F 40/30 (2020.01) [G06F 16/3347 (2019.01); G06F 40/20 (2020.01); G06N 3/045 (2023.01); G06N 3/08 (2013.01); G06N 20/00 (2019.01); G06F 40/216 (2020.01); G06F 40/284 (2020.01)] | 20 Claims |
|
1. A computer-implemented method to train machine learning models to perform reading comprehension, the method comprising:
obtaining, by a computing system comprising one or more computing devices, a training dataset comprising one or more training examples, each of the one or more training examples comprising:
a training natural language text passage,
a training natural language text question,
a training answer to the training natural language text question, and
a training program that comprises a sequence of operators that, when executed on the training natural language text passage by inputting the training natural language text passage to the training program, generates the training answer;
wherein obtaining the training dataset comprises:
identifying, by the computing system, a set of training programs that return the training answer;
selecting, by the computing system, the training program having a model probability that is a highest model probability among the set of training programs; and
applying, by the computing system, a decaying threshold such that the model probability of the training program must be at least the decaying threshold;
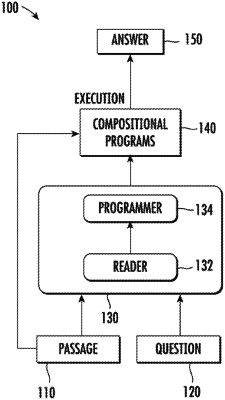
accessing, by the computing system, a machine-learned programmer model configured to generate a program based on language embeddings associated with an input natural language text passage and an input natural language text question, wherein the machine-learned programmer model comprises a plurality of parameters respectively having a plurality of values; and
modifying, by the computing system and based on at least one of the one or more training examples, one or more of the values of one or more of the parameters of the machine-learned programmer model to increase a probability that the machine-learned programmer model generates the training program in response to language embeddings generated from the training natural language text passage and the training natural language text question.
|