| CPC G06F 16/683 (2019.01) [G06F 16/61 (2019.01)] | 20 Claims |
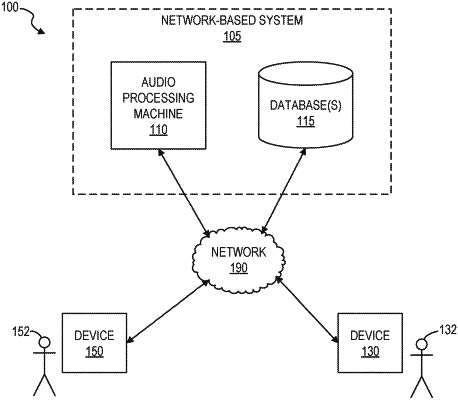
|
1. A computer-implemented method comprising:
determining, by at least one hardware processor, a representative audio content for a cluster, wherein the cluster comprises at least two audio contents;
loading, by the at least one hardware processor, the representative audio content into an index, wherein the representative audio content is stored in association with a hash value, and wherein the hash value is associated with a candidate reference identifier;
removing, by the at least one hardware processor, candidate reference identifiers that appear less than a threshold number of times;
in response to removing the candidate reference identifiers that appear less than a threshold number of times, generating a first comparison, by the at least one hardware processor, of a query audio content to each representative audio content associated with a remaining set of candidate reference identifiers, wherein the remaining set of candidate reference identifiers does not include the removed candidate reference identifiers, and wherein the first comparison is generated using a first matching criteria; and
matching, by the at least one hardware processor, the query audio content to one of the representative audio content based on the generated first comparison.
|