| CPC G06F 16/285 (2019.01) [G06F 18/214 (2023.01); G06F 18/2321 (2023.01); G06F 18/23213 (2023.01); G06F 18/24137 (2023.01); G06F 18/2433 (2023.01)] | 20 Claims |
|
1. A method comprising:
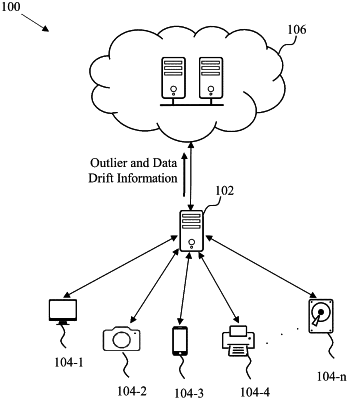
processing input data, at an edge system, based on baseline reference data, to obtain a plurality of representative points, wherein the input data comprises at least one of data received from a data source and/or prediction data obtained from a data model, and wherein the plurality of representative points correspond to segments of the input data derived using a predefined segment size;
clustering the plurality of representative points, at the edge system, to generate a plurality of clusters using a data clustering technique, wherein each cluster among the plurality of clusters comprises one or more representative points of the plurality of representative points;
modifying the predefined segment size when deviations are identified between multiple sets of clusters of the plurality of representative points prepared using different data clustering techniques;
detecting a first outlier cluster, at the edge system, from the plurality of clusters, based on at least one of a maximum distance of the plurality of clusters from a highest density cluster and/or comparison of quantity and values of the plurality of representative points with predefined rules, wherein a histogram algorithm is used to determine densities corresponding to the plurality of clusters;
identifying data drift, at the edge system, based on changes in densities of the plurality of clusters occurring over a predefined period of time;
generating a machine learning algorithm utilizing information corresponding to the first outlier cluster and the data drift; and
applying the machine learning algorithm to train the data model to update the baseline reference data.
|