| CPC G06F 16/258 (2019.01) [G06F 16/1794 (2019.01); G06F 16/27 (2019.01); G06F 16/273 (2019.01); G06F 16/275 (2019.01); G06F 16/278 (2019.01)] | 20 Claims |
|
1. A system for improved blockchain data indexing by decoupling compute and storage layers, the system comprising:
a multi-layer data platform for indexing on-chain data, the multi-layer data platform comprising one or more processors and non-transitory computer-readable media storing instructions that, when executed by the one or more processors, cause operations comprising;
populating a first dataset, wherein the first dataset is populated based on:
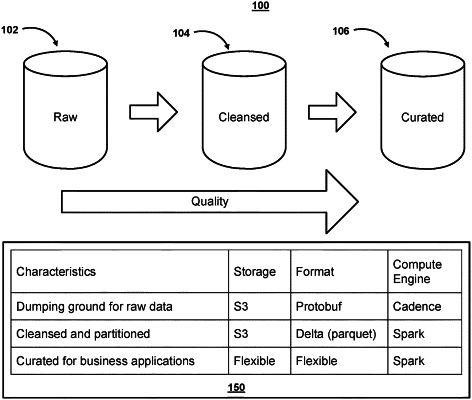
receiving first on-chain data from a blockchain node of a blockchain network, wherein the first on-chain data comprises hexadecimal encoded data from a first block of the blockchain network;
transforming the first on-chain data to a first format, and wherein the first format comprises data types with field names identified by a respective integer;
storing the first on-chain data, in the first dataset at a blockchain-interface layer, wherein the first dataset comprises the hexadecimal encoded data, and wherein the first dataset uses the first format; and
retrieving a first compute engine, wherein the first compute engine comprises a first workflow architecture, wherein the first workflow architecture comprises a first threshold for workflow throughout and a first threshold for a number of workflows;
populating a second dataset, wherein the second dataset is populated based on:
transforming the first on-chain data in the first format to a second format, wherein the second format comprises a columnar oriented format;
storing the first on-chain data, in the second dataset at a data lakehouse layer, wherein the second dataset comprises the first on-chain data and second on-chain data in the second format, and wherein the second on-chain data is from a second block on the blockchain network; and
retrieving a second compute engine, wherein the second compute engine comprises a second workflow architecture, wherein the second workflow architecture comprises a second threshold for workflow throughout and a second threshold for the number of workflows, wherein the second threshold for workflow throughput is higher than the first threshold for workflow throughput, and wherein the second threshold for the number of workflows is lower than the first threshold for the number of workflows; and
populating a third dataset, wherein the third dataset is populated based on:
transforming the first on-chain data and the second on-chain data to a third format, wherein the third format is selected based on an application;
storing the first on-chain data and the second on-chain data, in the third dataset at an application service layer; and
retrieving a third compute engine, wherein the third compute engine comprises the second workflow architecture.
|