| CPC G06F 16/243 (2019.01) [G06F 16/285 (2019.01); G06F 16/29 (2019.01); G06F 40/30 (2020.01); G06N 20/00 (2019.01)] | 20 Claims |
|
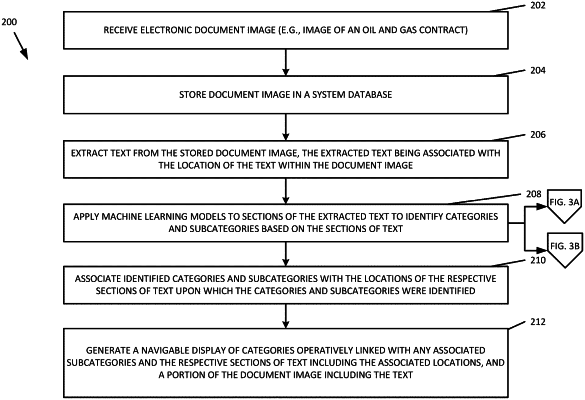
1. A method for linking similar documents, the method comprising:
generating, by a processor and based on a first document, a first feature in the first document associated with an ontology, the first feature including a portion of a first vector containing predetermined values;
generating, by the processor and based on a second document, a second feature in the second document associated with the ontology, the second feature including a portion of a second vector containing the predetermined values; and
linking, by the processor, the first document and the second document by the first feature and the second feature, the linking being based on a measure of similarity of the first vector to the second vector being within a defined threshold range;
wherein the first vector, the second vector, and the predetermined values are identified by a plurality of trained machine learning models executed on the first document and the second document, the plurality of trained machine learning models comprising a learned paragraph model trained to identify an ontological category and a learned sentence model trained to identify an ontological sub-category of the ontological category that, when executed sequentially, generate the first feature and the second feature, wherein an output of the learned paragraph model is an input to the learned sentence model.
|