| CPC H04N 21/8541 (2013.01) [H04N 21/44218 (2013.01)] | 17 Claims |
|
1. A computer-implemented method comprising:
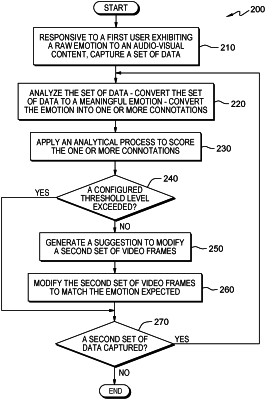
responsive to a first user exhibiting an emotion to an audio-visual content, capturing, by one or more processors, a set of sensor data from an IoT device worn by the first user to identify a first set of video frames of the audio-visual content the first user was watching when the first user exhibited the emotion;
converting, by the one or more processors, the emotion exhibited by the first user to the audio-visual content captured in the set of sensor data into one or more connotations using an emotional vector analytics technique and a supervised machine learning technique to attach the one or more connotations on a frame-by-frame basis;
generating, by the one or more processors, a score for the one or more connotations on a basis of similarity between the emotion exhibited by the first user and an emotion expected to be provoked by a producer of the audio-visual content using an analytical process;
determining, by the one or more processors, whether the score of the one or more connotations exceeds a pre-configured threshold level, wherein exceeding the pre-configured threshold level indicates that the emotion exhibited by the first user is similar to the emotion expected to be provoked by the producer and not exceeding the pre-configured threshold level indicates that the emotion exhibited by the first user is dissimilar to the emotion expected to be provoked by the producer; and
responsive to determining the score does not exceed the pre-configured threshold level, modifying, by the one or more processors, a second set of video frames based on the emotion expected to be exhibited by a second user.
|