| CPC H04N 19/114 (2014.11) [H04N 19/139 (2014.11); H04N 19/177 (2014.11)] | 26 Claims |
|
1. A method for video processing at a device, comprising:
receiving a bitstream comprising a set of video frames;
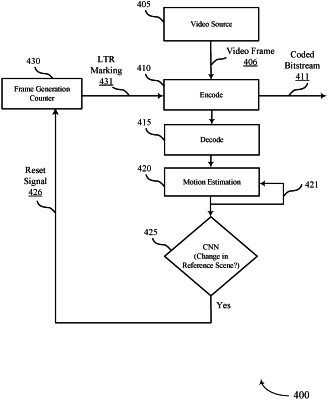
batching the set of video frames into separate batches of video frames, the batching comprising batching the set of video frames into a first subset of video frames and a second subset of video frames based at least in part on a change in a reference scene associated with the set of video frames, wherein the first subset of video frames comprises a first quantity of video frames after the change in the reference scene and the second subset comprises a second quantity of video frames following the first quantity of video frames and before a next change in the reference scene;
decoding the first subset of video frames using a video processing unit of the device;
selecting a training mode for a mode of operation for a neural processing unit based at least in part on the change in the reference scene, wherein training a learning model associated with the neural processing unit during the training mode is based at least in part on at least one decoded video frame of the decoded first subset of video frames;
selecting a generation mode for the mode of operation for the neural processing unit of the device based at least in part on the batching and header information associated with one or more frames of the first subset of video frames, the second subset of video frames, or both; and
generating, using the neural processing unit of the device, at least one video frame of the second subset of video frames during the generation mode based at least in part on at least one decoded video frame of the decoded first subset of video frames and the training of the learning model.
|