| CPC G10L 15/32 (2013.01) [G10L 15/18 (2013.01); G10L 15/22 (2013.01); G10L 15/30 (2013.01)] | 20 Claims |
|
1. A method implemented by one or more processors, the method comprising:
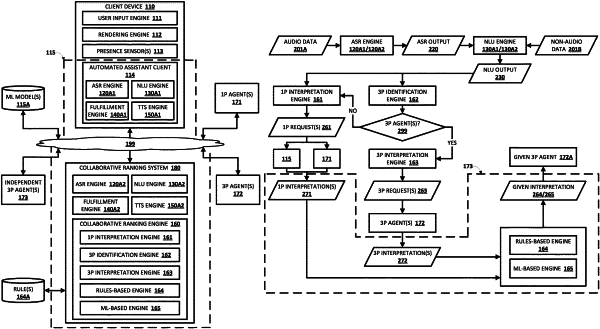
processing, using an automatic speech recognition (ASR) model, audio data that captures a spoken utterance of a user to generate ASR output, the audio data being generated by one or more microphones of a client device of the user, and the spoken utterance being directed to an automated assistant executed at least in part at the client device;
processing, using a natural language understanding (NLU) model, the ASR output, to generate NLU output;
determining, based on the NLU output, a plurality of first-party interpretations of the spoken utterance, each of the plurality of first-party interpretations being associated with a corresponding first-party predicted value indicative of a magnitude of confidence that each of the first-party interpretations are predicted to satisfy the spoken utterance;
identifying a given third-party agent capable of satisfying the spoken utterance;
transmitting, to the given third-party agent and over one or more networks, and based on the NLU output, one or more structured requests that, when received, causes the given third-party to determine a plurality of third-party interpretations of the spoken utterance, each of the plurality of third-party interpretations being associated with a corresponding third-party predicted value indicative of a magnitude of confidence that each of the third-party interpretations are predicted to satisfy the spoken utterance;
receiving, from the given third-party agent and over one or more of the networks, the plurality of third-party interpretations of the spoken utterance;
selecting, based on the corresponding first-party predicted values and the corresponding third-party predicted values, a given interpretation of the spoken utterance from among the plurality of first-party interpretations and the plurality third-party interpretations; and
causing the given third-party agent to satisfy the spoken utterance based on the given interpretation of the spoken utterance.
|