| CPC G10L 15/22 (2013.01) [G10L 15/02 (2013.01); G10L 15/063 (2013.01); G10L 15/18 (2013.01); G10L 19/00 (2013.01); G10L 2015/025 (2013.01); G10L 2015/088 (2013.01); G10L 15/142 (2013.01); G10L 2015/223 (2013.01)] | 20 Claims |
|
1. A computer-implemented method that when executed on data processing hardware causes the data processing hardware to perform operations comprising:
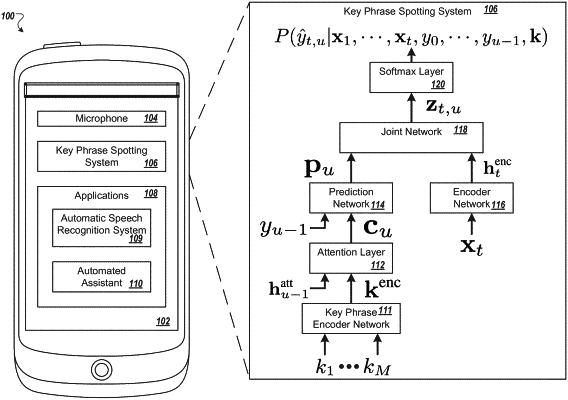
receiving, as output from a key phrase encoder network, a key phrase encoding for a sequence of target sub-word units representing a key phrase;
for each corresponding frame of multiple frames representing an incoming audio signal:
processing, by an acoustic encoder network, the corresponding frame to generate an encoder output that represents an acoustic encoding of the corresponding frame;
generating, using an attention mechanism, a context vector for the corresponding frame based on the key phrase encoding output from the key phrase encoder network;
generating, using a prediction network that receives the context vector generated for the corresponding frame and a non-blank label previously output by a final softmax layer as input, an output vector for the corresponding frame; and
predicting, using the output vector generated for the corresponding frame and the encoder output generated for the corresponding frame, a sub-word unit; and
determining whether the incoming audio signal encodes an utterance of the key phrase based on the sub-word units predicted for the multiple frames.
|